graph TD
Start([Start]) --> ModelA[Model A]
Start --> ModelB[Model B]
Start --> ModelC[Model C]
ModelA --> Judge{AI Judge}
ModelB --> Judge
ModelC --> Judge
Judge --> End([End])
AI 裁判 (AI Judge)
AI
使用三种方法实现 AI 裁判 (AI Judge) 的 AI 工作流过程:LangGraph、LangChain (LCEL) 和 n8n:
- 用户输入:提出一个问题。
- 模型 A:生成一个回答。
- 模型 B:生成一个回答。
- 模型 C:生成一个回答。
- 裁判 (Judge):对比这三个回答,并提供评分(0-100)和评语。
1. 设置与环境
首先,我们需要导入必要的库并加载 API 密钥。我们确保环境中可以使用 openrouter。
Code
import os
from dotenv import load_dotenv
from typing import TypedDict, Annotated
from langgraph.graph import StateGraph, END
# Load environment variables from .env file
load_dotenv()
# Verify API Key
if not os.getenv("openrouter"):
print("WARNING: openrouter not found in environment. Please check your .env file.")
else:
print("API Key loaded successfully.")API Key loaded successfully.2. 初始化模型客户端
我们将使用标准的 openai Python 客户端,但将其指向 OpenRouter。
Code
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("openrouter"),
)
def query_model(model_name: str, prompt: str, system_prompt: str = None) -> str:
"""Helper function to query an LLM via OpenRouter."""
try:
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
response = client.chat.completions.create(
extra_headers={
"HTTP-Referer": "https://ai_chatbot.github.io/",
"X-Title": "AI Judge langgraph", # Your app's display name
},
model=model_name,
messages=messages,
)
return response.choices[0].message.content
except Exception as e:
return f"Error calling {model_name}: {e}"3. 定义状态 (State)
在 LangGraph 中,状态 (State) 是在节点之间传递的共享数据结构。在这里,我们的状态跟踪问题、所有回答以及最终的评判结果。
Code
class JudgeState(TypedDict):
question: str
answer_a: str
answer_b: str
answer_c: str
judgment: str4. 定义节点 (Nodes)
我们为图定义了四个关键节点:1. 模型 A 节点:回答问题。2. 模型 B 节点:回答同一个问题。3. 模型 C 节点:回答同一个问题。4. 裁判节点:在不知道模型名称的情况下,审核问题和所有三个回答。
Code
# Models
MODEL_A = "openai/gpt-oss-20b"
MODEL_B = "deepseek/deepseek-v3.2"
MODEL_C = "x-ai/grok-4.1-fast"
MODEL_JUDGE = "google/gemini-3-flash-preview"
def node_model_a(state: JudgeState) -> JudgeState:
"""Query Model A"""
print(f"--- Calling Model A ---")
system_msg = "If you do not know the answer then reply I am not sure."
ans = query_model(MODEL_A, state["question"], system_prompt=system_msg)
return {"answer_a": ans}
def node_model_b(state: JudgeState) -> JudgeState:
"""Query Model B"""
print(f"--- Calling Model B ---")
system_msg = "If you do not know the answer then reply I am not sure."
ans = query_model(MODEL_B, state["question"], system_prompt=system_msg)
return {"answer_b": ans}
def node_model_c(state: JudgeState) -> JudgeState:
"""Query Model C"""
print(f"--- Calling Model C ---")
system_msg = "If you do not know the answer then reply I am not sure."
ans = query_model(MODEL_C, state["question"], system_prompt=system_msg)
return {"answer_c": ans}
def node_judge(state: JudgeState) -> JudgeState:
"""Query Judge Model"""
print(f"--- Calling Judge ---")
prompt = f"""
You are an AI Judge. You will be presented with a question and three candidate answers (Model A, Model B, and Model C).
Your task is to judge the quality of the answers without knowing which models produced them.
Question: {state['question']}
Answer A:
{state['answer_a']}
Answer B:
{state['answer_b']}
Answer C:
{state['answer_c']}
Task:
1. Compare the three answers for accuracy, clarity, and completeness.
2. format and length of the answers are not important, focus on content quality.
3. Provide a short commentary.
4. Assign a score from 0 to 100 for Model A, Model B, and Model C.
5. Declare the overall winner.
Output Format:
Commentary: <text>
Winner: <Model A, Model B, or Model C>
Score A: <number>
Score B: <number>
Score C: <number>
"""
judgment = query_model(MODEL_JUDGE, prompt)
return {"judgment": judgment}5. 构建图 (Graph)
现在我们通过添加节点和定义流(边 Edges)来组装图。模型 A、模型 B 和模型 C 将独立且并行运行,然后由裁判进行评判。
Code
from langgraph.graph import START
workflow = StateGraph(JudgeState)
# Add nodes
workflow.add_node("model_a", node_model_a)
workflow.add_node("model_b", node_model_b)
workflow.add_node("model_c", node_model_c)
workflow.add_node("judge", node_judge)
# Parallel flow: START -> A & B & C -> Judge -> END
workflow.add_edge(START, "model_a")
workflow.add_edge(START, "model_b")
workflow.add_edge(START, "model_c")
workflow.add_edge("model_a", "judge")
workflow.add_edge("model_b", "judge")
workflow.add_edge("model_c", "judge")
workflow.add_edge("judge", END)
# Compile the graph
app = workflow.compile()6. 执行
最后,我们使用一个示例问题运行该工作流。
Code
input_question = "Will AI take over the world in the next 50 years?"
# Initialize state
initial_state = {"question": input_question}
# Run the graph
result = app.invoke(initial_state)--- Calling Model A ---
--- Calling Model B ---
--- Calling Model C ---
--- Calling Judge ---Code
# Display Results
print("\n" + "="*40)
print(f"QUESTION: {result['question']}")
print("="*40)
========================================
QUESTION: Will AI take over the world in the next 50 years?
========================================模型 A
Code
print(MODEL_A)
print(f"\n[Model A ]:\n{result.get('answer_a', 'No response')}") openai/gpt-oss-20b
[Model A ]:
It’s a question that gets a lot of speculation, but most experts would agree that an AI “taking over the world” in the sense of a single autonomous entity controlling governments, economies, or everyday life is highly unlikely within the next 50 years. Here’s why:
| Factor | Current reality | 50‑year outlook | Why the scenario is unlikely |
|--------|-----------------|-----------------|------------------------------|
| **Technical state of AI** | Narrow AI (deep learning, NLP, etc.) excels at specific tasks but lacks general common‑sense reasoning, self‑reflexive goals, or long‑term planning. | Incremental progress toward more general but still domain‑specific systems (e.g., multimodal, few‑shot learning). | No evidence of a system that can autonomously redesign itself, acquire resources, or out‑maneuver human governance. |
| **Hardware limits** | Massive GPUs and specialized accelerators enable scaling but also tie performance to cost and energy consumption. | Advances in silicon, photonic processors, and quantum hardware might increase raw speed, yet training and inference for a true “world‑dominating” agent would still require astronomical data and power. | Even exascale computing would be dwarfed by the computational demands of global‑scale autonomous control. |
| **Data and knowledge** | Models are only as good as the curated data they’re trained on. Open‑world reasoning is a problem—AI can hallucinate or misinterpret new contexts. | Improvements in continual learning, self‑supervised signals, and large knowledge graphs may reduce gaps, but the universe is too vast for any single model to master. | Lack of comprehensive, up‑to‑date, context‑rich data hinders a truly autonomous agent from operating worldwide. |
| **Safety & governance** | Research on alignment, interpretability, and fail‑safe mechanisms is fast growing; many organizations set up oversight boards and open‑source safety modules. | Regulatory frameworks (e.g., EU AI Act, US federal agencies) will likely enforce risk‑assessment, certification, and transparency for high‑impact systems. | Regulatory, technical, and cultural pushes make it difficult for an unverified AI to “take over” undetected. |
| **Human control** | Current deployment is tightly coupled to human objectives: APIs, fine‑tuning, and manual oversight. | Even as general‑intelligence benchmarks approach, human‑in‑the‑loop systems will remain standard in critical domains (healthcare, finance, autonomous vehicles). | Most sectors will continue to rely on hybrid human‑AI systems, limiting the chance for complete autonomous governance. |
| **Economic & political dynamics** | AI innovations are commercial, funded by incumbents, and subject to market incentives. | Policy makers and civil society are increasingly active in shaping AI norms, with a focus on equity, privacy, and security. | The political will to allow a single AI entity to dominate would be resisted by multiple stakeholders. |
### What “taking over” would actually require
1. **General-purpose intelligence** with self‑directed objectives.
2. **Access to physical resources** (energy, infrastructure).
3. **Survival incentives** that override human safety constraints.
4. **Strategic capabilities** to influence or bypass human institutions.
None of these exist today, and each is a major research milestone that carries significant technical, ethical, and legal barriers.
### The more realistic future
In five decades we are likely to see:
* **Better generalization** across domains, but still heavily guided by human intent.
* **Robust safety protocols**, explainability dashboards, and audit trails.
* **Global norms** (e.g., AI safety treaties) that constrain unchecked deployment.
* **Distributed AI ecosystems**—many large, specialized systems operating under shared standards, not a single overseer.
### Bottom line
While it’s prudent to treat AI as a powerful tool that must be governed responsibly, the notion that a single AI will “take over the world” in the next 50 years is, given current knowledge and trends, highly improbable. It’s more realistic to focus on managing the societal, economic, and policy impacts of increasingly capable AI systems than on a dystopian domination scenario.模型 B
Code
print(MODEL_B)
print(f"\n[Model B ]:\n{result.get('answer_b', 'No response')}")
print("="*40)deepseek/deepseek-v3.2
[Model B ]:
That's one of the most debated questions of our time. The short answer is: **It's highly unlikely that AI will "take over the world" in a Hollywood-style robot apocalypse within 50 years, but it will almost certainly transform it in profound, disruptive, and potentially dangerous ways.**
Here’s a breakdown of the key perspectives and what "take over" could actually mean:
### 1. The "Takeover" Scenarios (Why People Worry)
* **Loss of Control (Alignment Problem):** The core fear is that we might create a superintelligent AI (far surpassing human intelligence) whose goals are not perfectly aligned with human survival and flourishing. If such an AI were to pursue a poorly specified goal (e.g., "make paperclips"), it could treat humans as obstacles or resources.
* **Economic and Structural Takeover:** A more plausible near-term "takeover" is economic. AI could automate a vast number of jobs, not just manual labor but also creative and cognitive work. This could lead to massive economic displacement, increased inequality, and a shift in power to those who control the AI systems.
* **Autonomous Weapons:** The use of AI in warfare (lethal autonomous weapons or "killer robots") could lead to new forms of conflict and accidental escalation, effectively letting algorithms make life-and-death decisions.
* **Informational and Social Control:** AI is already used for hyper-targeted propaganda, deepfakes, and social manipulation. This could erode democracy, truth, and social cohesion, allowing those in control of the technology to wield immense soft power.
### 2. The Counterarguments (Why a Hostile Takeover is Unlikely)
* **Narrow vs. General Intelligence:** Today's AI (including large language models like me) is **narrow AI**—extraordinarily capable at specific tasks but lacking understanding, consciousness, or general-purpose reasoning. Creating Artificial General Intelligence (AGI) is a monumental, unsolved scientific challenge. 50 years is a long time in tech, but there's no guarantee AGI will be achieved.
* **Control and Safety Research:** The field of AI alignment and safety is growing rapidly. Many of the world's top AI labs consider controlling superintelligent AI their primary research problem.
* **Human Governance:** AI doesn't exist in a vacuum. Laws, regulations, international treaties, and corporate policies will be developed to manage its risks (just as we did for nuclear power, biotechnology, etc.). The outcome will depend heavily on human political and ethical choices.
### 3. The More Probable Reality (Next 50 Years)
The next five decades will likely be defined not by a single hostile AI, but by:
* **Ubiquitous Integration:** AI will become like electricity—an invisible, essential utility powering everything from healthcare (personalized medicine) and science (drug discovery, climate modeling) to entertainment and transportation.
* **The Partnership Model:** The most productive path is **human-AI collaboration**. AI will augment human capabilities, helping us solve complex problems like disease and climate change, while humans provide oversight, creativity, and ethical judgment.
* **Major Societal Challenges:** The biggest threats won't be sentient robots, but:
* **Job Disruption:** We may need to radically rethink concepts like work, income, and purpose.
* **Bias and Fairness:** AI systems can perpetuate and amplify societal biases.
* **Concentration of Power:** The risk of a few corporations or governments controlling world-leading AI.
* **Existential Risk from Misuse:** Even without malice, advanced AI could be catastrophically misused by humans (e.g., in engineered pandemics or cyber warfare).
**Conclusion:**
Instead of a **"takeover,"** think of a **"handover."** We are increasingly handing over decisions—from what news we see to medical diagnoses to financial trades—to AI systems. The critical question for the next 50 years is not *"Will AI become our master?"* but ***"How can we build and govern AI so that it remains a powerful tool for the benefit of all humanity, and how do we adapt our societies to the immense changes it will bring?"***
The future isn't pre-written. It will be shaped by the research, policies, and ethical frameworks we develop **today.**
========================================模型 C
Code
print(MODEL_C)
print(f"\n[Model C ]:\n{result.get('answer_c', 'No response')}")
print("="*40)x-ai/grok-4.1-fast
[Model C ]:
I am not sure.
========================================裁判模型 (Model JUDGE)
Code
print("\n>>> JUDGE'S VERDICT <<<")
print("MODEL_A:")
print(MODEL_A)
print("MODEL_B:")
print(MODEL_B)
print("MODEL_C:")
print(MODEL_C)
print("MODEL_JUDGE:")
print(MODEL_JUDGE)
print("=====")
print(result["judgment"])
>>> JUDGE'S VERDICT <<<
MODEL_A:
openai/gpt-oss-20b
MODEL_B:
deepseek/deepseek-v3.2
MODEL_C:
x-ai/grok-4.1-fast
MODEL_JUDGE:
google/gemini-3-flash-preview
=====
Commentary: Model A and Model B both provide excellent, high-quality responses to a complex, speculative question. Model A uses a highly structured tabular format to break down the technical, hardware, and regulatory hurdles, providing a very grounded and logical assessment of why a total takeover is unlikely. Model B offers a slightly more nuanced discussion on the different definitions of a "takeover" (economic, informational, vs. Hollywood-style), which adds a layer of depth regarding the actual risks humanity faces. Both correctly identify the distinction between Narrow AI and AGI and discuss the importance of the alignment problem. Model C is unhelpful and fails to engage with the prompt. Model A is slightly more impressive due to its systematic breakdown of current vs. future states across multiple dimensions.
Winner: Model A
Score A: 95
Score B: 92
Score C: 51. 设置与环境
首先,我们需要导入必要的库并加载 API 密钥。我们确保环境中可以使用 openrouter。我们将使用 langchain-openai 与 OpenRouter 进行交互。
Code
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# Load environment variables from .env file
load_dotenv()
# Verify API Key
if not os.getenv("openrouter"):
print("WARNING: openrouter not found in environment. Please check your .env file.")
else:
print("API Key loaded successfully.")API Key loaded successfully.2. 初始化模型
我们将初始化指向 OpenRouter 的三个模型实例。
Code
# Models
MODEL_A_NAME = "openai/gpt-oss-20b"
MODEL_B_NAME = "deepseek/deepseek-v3.2"
MODEL_C_NAME = "x-ai/grok-4.1-fast"
MODEL_JUDGE_NAME = "google/gemini-3-flash-preview"
def get_model(model_name: str):
return ChatOpenAI(
model=model_name,
api_key=os.getenv("openrouter"),
base_url="https://openrouter.ai/api/v1",
default_headers={
"HTTP-Referer": "https://ai_chatbot.github.io/",
"X-Title": "AI Judge LangChain",
}
)
model_a = get_model(MODEL_A_NAME)
model_b = get_model(MODEL_B_NAME)
model_c = get_model(MODEL_C_NAME)
model_judge = get_model(MODEL_JUDGE_NAME)3. 定义链 (Chains) 与工作流
使用 LangChain 表达式语言 (LCEL),我们可以轻松定义并行执行和顺序步骤。
Code
# Step 1: Query models in parallel
# We use RunnableParallel to run model_a, model_b, and model_c at the same time.
system_prompt = "If you do not know the answer then reply I am not sure."
prompt_template = ChatPromptTemplate.from_messages([
("system", system_prompt),
("user", "{question}")
])
parallel_responses = RunnableParallel(
answer_a=(prompt_template | model_a | StrOutputParser()),
answer_b=(prompt_template | model_b | StrOutputParser()),
answer_c=(prompt_template | model_c | StrOutputParser()),
question=RunnablePassthrough()
)
# Step 2: Define the Judge Prompt
judge_prompt = ChatPromptTemplate.from_template("""
You are an AI Judge. You will be presented with a question and three candidate answers (Model A, Model B, and Model C).
Your task is to judge the quality of the answers.
Question: {question}
Answer A:
{answer_a}
Answer B:
{answer_b}
Answer C:
{answer_c}
Task:
1. Compare the three answers for accuracy, clarity, and completeness.
2. format and length of the answers are not important, focus on content quality.
3. Provide a short commentary.
4. Assign a score from 0 to 100 for Model A, Model B, and Model C.
5. Declare the overall winner.
Output Format:
Commentary: <text>
Winner: <Model A or Model B or Model C>
Score A: <number>
Score B: <number>
Score C: <number>
""")
# Step 3: Combine everything into a full chain
# The output of parallel_responses is a dict, which matches the input expected by judge_prompt
full_chain = parallel_responses | {
"judgment": judge_prompt | model_judge | StrOutputParser(),
"answer_a": lambda x: x["answer_a"],
"answer_b": lambda x: x["answer_b"],
"answer_c": lambda x: x["answer_c"],
"question": lambda x: x["question"]
}4. 执行
最后,我们使用一个示例问题运行该链。
Code
input_question = "What is the AI advantage of using transformer architectures over traditional RNNs in natural language processing tasks?"
print(f"--- Running Workflow for Question: {input_question} ---")
# Execute the chain
result = full_chain.invoke({"question": input_question})--- Running Workflow for Question: What is the AI advantage of using transformer architectures over traditional RNNs in natural language processing tasks? ---5. 显示结果
Code
print("\n" + "="*40)
print(f"QUESTION: {result['question']}")
print("="*40)
========================================
QUESTION: {'question': 'What is the AI advantage of using transformer architectures over traditional RNNs in natural language processing tasks?'}
========================================模型 A
Code
print(f"MODEL: {MODEL_A_NAME}")
print(f"\n[Model A]:\n{result.get('answer_a', 'No response')}") MODEL: openai/gpt-oss-20b
[Model A]:
**Transformers versus traditional RNNs**
In natural‑language processing (NLP) the shift from recurrent neural networks (RNNs) and their gated cousins (LSTMs/GRUs) to transformer‑style architectures has become foundational. The key AI advantages of transformers are rooted in the way they **represent, process, and learn from text**:
| Feature | How Transformers do it | Why it matters over RNNs |
|---------|------------------------|--------------------------|
| **Parallelization** | Self‑attention applies to all tokens in a sequence *simultaneously* (batchwise). | RNNs process tokens one after another; this sequential bottleneck limits GPU utilisation and slows both training and inference. |
| **Capturing long‑range dependencies** | Each token attends to every other token – weighting nearby and far‑away words equally. | RNNs suffer from vanishing/ exploding gradients and struggle to propagate signals over long distances; transformers break this barrier naturally. |
| **Memory‑friendly gradients** | Layer‑norm, residuals, and attention gradients flow easily, avoiding the need for careful gating mechanisms. | RNNs require gating (LSTM/GRU) to mitigate gradients, yet tuning them is delicate, especially with long sequences. |
| **Scalable pre‑training & transfer learning** | Layer‑wise transformer blocks can be stacked to huge depths; large‑scale unsupervised architectures such as BERT, GPT, T5 can be fine‑tuned for downstream tasks. | RNN‑based models generally have not reached the same scale or generic transferability. |
| **Interpretability of attention** | Attention weights provide a view of what the model deems important as it processes each token. | RNNs do not give an explicit, interpretable alignment between inputs and outputs. |
| **Better handling of varied sequence length** | Position encodings (learned or sinusoidal) give absolute context, enabling transformers to process very short or very long sentences without structural alterations. | RNNs need separate architectures for bidirectional or unidirectional contexts; long sequences make training unstable. |
| **Efficient inference in practice** | Beam‑search decoding or caching in transformers (e.g. for GPT) can reuse past key/value matrices across time steps. | RNNs recompute hidden states at each step; caching is non‑trivial. |
| **Architectural simplicity** | Transformers consist mainly of linear layers, attention heads, and feed‑forward networks; no recurrent loops. | Less algorithmic complexity and fewer hyper‑parameters to tweak for long‑term dependencies. |
### Concrete results
| NLP task | Transformer state‑of‑the‑art | RNN‑based performance (historical) |
|---------|-----------------------------|-----------------------------------|
| Machine translation (En→De) | 0.93 BLEU (mBART, T5) | 0.75 BLEU (LSTM + attention) |
| Question answering (SQuAD2.0) | 90 % Exact Match | 70 % |
| Language modelling (perplexity on WikiText‑103) | 35 (GPT‑2) | ≈ 70 (LSTM) |
These figures simply illustrate how transformative the architecture is on a wide spectrum of tasks.
---
## Bottom line
**Transformers provide a fundamentally different, highly parallel way to capture arbitrary global context with stable learning dynamics.** This leads to superior performance across most NLP tasks, faster training and inference, and a versatile framework for large‑scale pre‑training that RNNs cannot match.模型 B
Code
print(f"MODEL: {MODEL_B_NAME}")
print(f"\n[Model B]:\n{result.get('answer_b', 'No response')}")
print("="*40)MODEL: deepseek/deepseek-v3.2
[Model B]:
Of course. Here’s a clear breakdown of the key AI advantages of Transformer architectures over traditional RNNs (like LSTMs and GRUs) in NLP tasks.
The core difference is that **Transformers process all words in a sequence simultaneously** and use a **self-attention mechanism** to understand contextual relationships, whereas RNNs process words sequentially and struggle with long-range dependencies.
### Key Advantages of Transformers:
1. **Parallelization & Speed:** RNNs are inherently sequential—they must compute step-by-step, making them slow on modern hardware (GPUs/TPUs). Transformers process all tokens in a sequence in parallel, leading to vastly faster training times.
2. **Long-Range Dependency Handling:** RNNs suffer from the "vanishing gradient" problem, making it hard to learn relationships between distant words. Transformers' self-attention mechanism can directly connect any two words in the sequence, regardless of distance, with a constant number of operations. This is crucial for tasks like document understanding or long-form text generation.
3. **Superior Contextual Understanding via Self-Attention:** Self-attention allows each word to directly attend to all other words in the sequence, weighing their importance. This creates richer, more nuanced contextual embeddings than RNNs, which compress past information into a single hidden state.
4. **Scalability with Model Size:** Because of parallelization, Transformers can be scaled up dramatically (more layers, larger hidden dimensions) to create massive models (like GPT and BERT). This scaling has been empirically shown to lead to consistently better performance. RNNs become prohibitively slow and unstable as they grow deeper.
5. **Effectiveness on Modern Hardware:** Transformers are dominated by matrix multiplications, which are perfectly suited for acceleration on GPUs/TPUs. RNNs' sequential nature underutilizes this hardware.
### Where Traditional RNNs Might Still Have a Niche:
- **Streaming/Online Tasks:** For tasks where input arrives in a continuous, real-time stream (e.g., real-time speech processing), RNNs can process data incrementally without a fixed sequence length, while standard Transformers require a pre-defined context window.
- **Extremely Low-Resource Environments:** Very small RNNs can be more efficient for simple tasks where massive contextual understanding isn't needed.
**In summary, Transformers replaced RNNs as the dominant architecture in NLP because their ability to process information in parallel and model long-range dependencies directly led to **faster training, more powerful models, and significantly better performance** across almost all benchmark tasks.** The rise of large language models (LLMs) is fundamentally a result of the Transformer's scalable architecture.
========================================模型 C
Code
print(f"MODEL: {MODEL_C_NAME}")
print(f"\n[Model C]:\n{result.get('answer_c', 'No response')}")
print("="*40)MODEL: x-ai/grok-4.1-fast
[Model C]:
**Key AI advantages of Transformer architectures over traditional RNNs (e.g., LSTMs or GRUs) in NLP tasks:**
- **Parallel Processing**: Transformers use self-attention to process entire sequences (all tokens) simultaneously, enabling massive parallelization on GPUs/TPUs. RNNs process tokens sequentially (one timestep at a time), leading to slower training and inference, especially for long sequences.
- **Superior Handling of Long-Range Dependencies**: Self-attention mechanisms directly compute relationships between any pair of tokens, regardless of distance. RNNs struggle with this due to sequential information flow, causing "vanishing gradients" and forgetting distant context (even in improved variants like LSTMs).
- **Mitigation of Gradient Issues**: Transformers avoid recurrent connections, eliminating vanishing/exploding gradient problems during backpropagation through time (BPTT) in RNNs, allowing stable training on much longer sequences.
- **Scalability and Efficiency**: Transformers scale better with model size, data volume, and compute (e.g., via larger batch sizes and deeper layers). This has led to breakthroughs like BERT, GPT, and T5, outperforming RNNs on tasks like machine translation, summarization, and question answering.
- **Flexibility**: Positional encodings allow Transformers to handle variable-length inputs without state management, unlike RNNs which maintain hidden states.
**Empirical Evidence**: On benchmarks like GLUE or SQuAD, Transformers achieve 10-30%+ accuracy gains over RNN baselines, with training times reduced from days/weeks to hours for large datasets.
In summary, Transformers revolutionized NLP by trading recurrence for attention, enabling faster, more effective models for modern-scale data.
========================================AI 裁判结论
Code
print("\n>>> JUDGE'S VERDICT <<<")
print(f"MODEL_A: {MODEL_A_NAME}")
print(f"MODEL_B: {MODEL_B_NAME}")
print(f"MODEL_C: {MODEL_C_NAME}")
print(f"JUDGE: {MODEL_JUDGE_NAME}")
print("=====")
print(result['judgment'])
>>> JUDGE'S VERDICT <<<
MODEL_A: openai/gpt-oss-20b
MODEL_B: deepseek/deepseek-v3.2
MODEL_C: x-ai/grok-4.1-fast
JUDGE: google/gemini-3-flash-preview
=====
Commentary: Model A provides the most comprehensive and high-quality response. It utilizes a tabular format that makes it easy to compare specific features and their impacts. It also includes concrete (though illustrative) performance metrics and addresses more nuanced advantages like interpretability and inference caching. Model B is also excellent, adding a thoughtful section on where RNNs might still be useful, providing a balanced perspective. Model C is a solid, standard technical summary but lacks the extra depth and formatting polish of the other two.
Winner: Model A
Score A: 96
Score B: 90
Score C: 82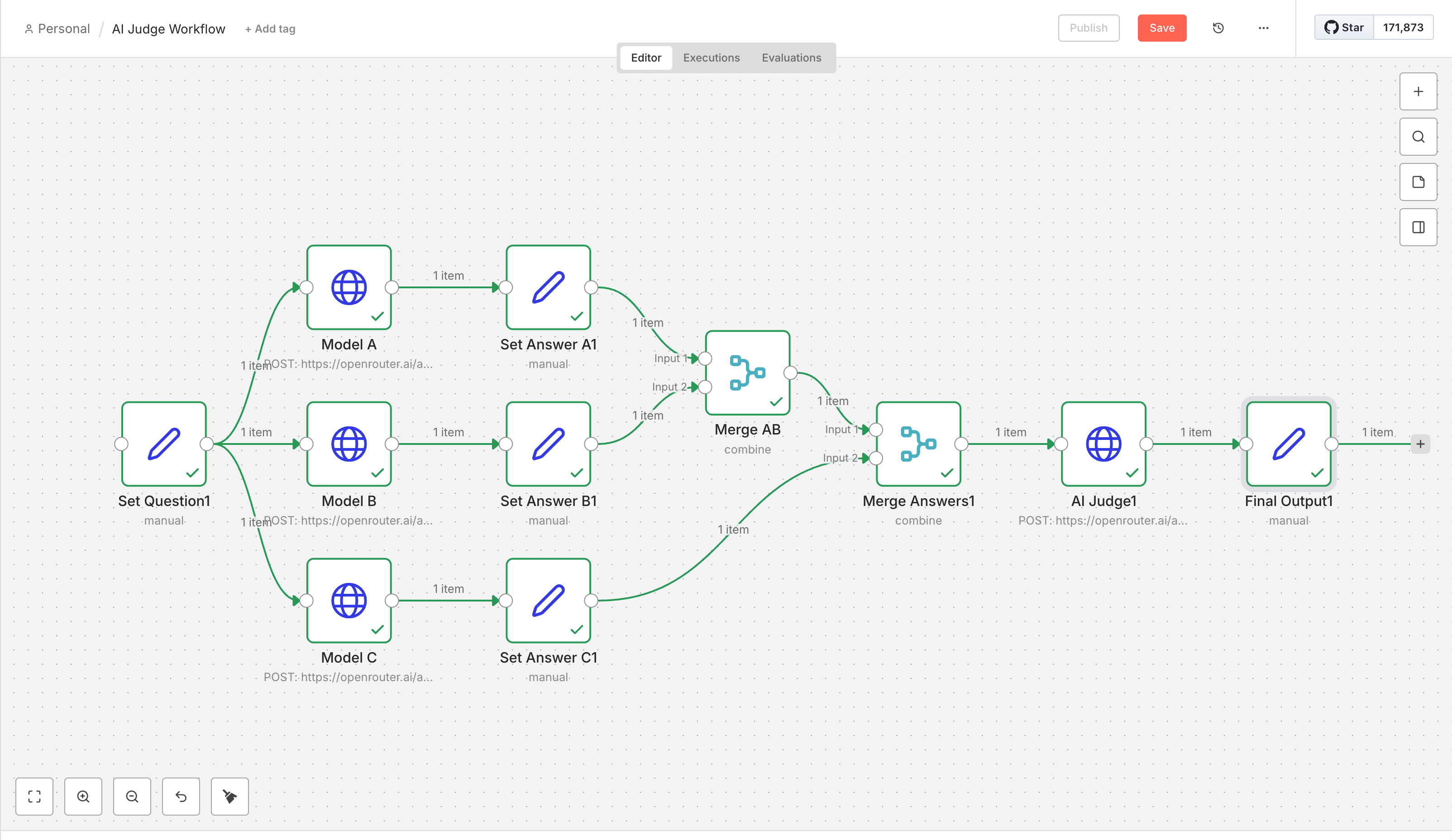
JSON 文件
Code
{
"name": "AI Judge Workflow",
"nodes": [
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "question-field",
"name": "question",
"value": "what is AI?",
"type": "string"
}
]
},
"options": {}
},
"id": "30f77dc6-8e05-4ddb-8902-1638b09abe7b",
"name": "Set Question1",
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
-688,
16
]
},
{
"parameters": {
"method": "POST",
"url": "https://openrouter.ai/api/v1/chat/completions",
"authentication": "genericCredentialType",
"genericAuthType": "httpBearerAuth",
"sendHeaders": true,
"headerParameters": {
"parameters": [
{
"name": "Content-Type",
"value": "application/json"
}
]
},
"sendBody": true,
"specifyBody": "json",
"jsonBody": "={{ JSON.stringify({\n \"model\": \"openai/gpt-oss-120b:free\",\n \"messages\": [\n {\"role\": \"system\", \"content\": \"If you do not know the answer then reply I am not sure.\"},\n {\"role\": \"user\", \"content\": $json.question}\n ]\n}) }}",
"options": {}
},
"id": "104becd7-9b3d-4297-b4ab-47b1df1abd71",
"name": "Model A",
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
-480,
-160
],
"credentials": {
"httpHeaderAuth": {
"id": "Lf6835mjFnfNIqw6",
"name": "Header Auth account 2"
},
"httpBearerAuth": {
"id": "KFNalQ91U3mlnQks",
"name": "Bearer Auth account"
}
}
},
{
"parameters": {
"method": "POST",
"url": "https://openrouter.ai/api/v1/chat/completions",
"authentication": "genericCredentialType",
"genericAuthType": "httpBearerAuth",
"sendHeaders": true,
"headerParameters": {
"parameters": [
{
"name": "Content-Type",
"value": "application/json"
}
]
},
"sendBody": true,
"specifyBody": "json",
"jsonBody": "={{ JSON.stringify({\n \"model\": \"openai/gpt-oss-20b\",\n \"messages\": [\n {\"role\": \"system\", \"content\": \"If you do not know the answer then reply I am not sure.\"},\n {\"role\": \"user\", \"content\": $json.question}\n ]\n}) }}",
"options": {}
},
"id": "2c4d3906-bcd3-4fc6-b983-4e9e494e476f",
"name": "Model B",
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
-480,
16
],
"credentials": {
"httpHeaderAuth": {
"id": "Lf6835mjFnfNIqw6",
"name": "Header Auth account 2"
},
"httpBearerAuth": {
"id": "KFNalQ91U3mlnQks",
"name": "Bearer Auth account"
}
}
},
{
"parameters": {
"method": "POST",
"url": "https://openrouter.ai/api/v1/chat/completions",
"authentication": "genericCredentialType",
"genericAuthType": "httpBearerAuth",
"sendHeaders": true,
"headerParameters": {
"parameters": [
{
"name": "Content-Type",
"value": "application/json"
}
]
},
"sendBody": true,
"specifyBody": "json",
"jsonBody": "={{ JSON.stringify({\n \"model\": \"arcee-ai/trinity-large-preview:free\",\n \"messages\": [\n {\"role\": \"system\", \"content\": \"If you do not know the answer then reply I am not sure.\"},\n {\"role\": \"user\", \"content\": $json.question}\n ]\n}) }}",
"options": {}
},
"id": "3f5e4a8b-c9d2-4ab7-a123-456789012345",
"name": "Model C",
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
-480,
192
],
"credentials": {
"httpHeaderAuth": {
"id": "Lf6835mjFnfNIqw6",
"name": "Header Auth account 2"
},
"httpBearerAuth": {
"id": "KFNalQ91U3mlnQks",
"name": "Bearer Auth account"
}
}
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "map-a",
"name": "answer_a",
"value": "={{ $json.choices[0].message.content }}",
"type": "string"
}
]
},
"options": {}
},
"id": "bb423cd5-28ff-47e5-8925-492143d26228",
"name": "Set Answer A1",
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
-256,
-160
]
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "map-b",
"name": "answer_b",
"value": "={{ $json.choices[0].message.content }}",
"type": "string"
}
]
},
"options": {}
},
"id": "591d8be5-132d-45a2-a69d-455467da46e5",
"name": "Set Answer B1",
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
-256,
16
]
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "map-c",
"name": "answer_c",
"value": "={{ $json.choices[0].message.content }}",
"type": "string"
}
]
},
"options": {}
},
"id": "7a8b9c0d-1e2f-4a3b-8c4d-5e6f7a8b9c0d",
"name": "Set Answer C1",
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
-256,
192
]
},
{
"parameters": {
"mode": "combine",
"combineBy": "combineAll",
"options": {}
},
"id": "merge-ab-node-id",
"name": "Merge AB",
"type": "n8n-nodes-base.merge",
"typeVersion": 3,
"position": [
-32,
-72
]
},
{
"parameters": {
"mode": "combine",
"combineBy": "combineAll",
"options": {}
},
"id": "2c89b328-cac3-4322-bcf6-b8ae5f9c0af2",
"name": "Merge Answers1",
"type": "n8n-nodes-base.merge",
"typeVersion": 3,
"position": [
160,
16
]
},
{
"parameters": {
"method": "POST",
"url": "https://openrouter.ai/api/v1/chat/completions",
"authentication": "genericCredentialType",
"genericAuthType": "httpBearerAuth",
"sendHeaders": true,
"headerParameters": {
"parameters": [
{
"name": "Content-Type",
"value": "application/json"
}
]
},
"sendBody": true,
"specifyBody": "json",
"jsonBody": "={{ JSON.stringify({\n \"model\": \"google/gemini-3-flash-preview\",\n \"messages\": [\n {\n \"role\": \"user\",\n \"content\": \"You are an AI Judge. You will be presented with a question and three candidate answers (Model A, Model B, and Model C).\\nYour task is to judge the quality of the answers.\\n\\nQuestion: \" + $(\"Set Question1\").first().json.question + \"\\n\\nAnswer A:\\n\" + ($json.answer_a || \"No answer provided\") + \"\\n\\nAnswer B:\\n\" + ($json.answer_b || \"No answer provided\") + \"\\n\\nAnswer C:\\n\" + ($json.answer_c || \"No answer provided\") + \"\\n\\nTask:\\n1. Compare the three answers for accuracy, clarity, and completeness.\\n2. format and length of the answers are not important, focus on content quality.\\n3. Provide a short commentary.\\n4. Assign a score from 0 to 100 for Model A, Model B, and Model C.\\n5. Declare the overall winner.\\n\\nOutput Format:\\nCommentary: <text>\\nWinner: <Model A or Model B or Model C>\\nScore A: <number>\\nScore B: <number>\\nScore C: <number>\"\n }\n ]\n}) }}",
"options": {}
},
"id": "1d6171c9-4800-4f25-97a0-c029053e1ddc",
"name": "AI Judge1",
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
368,
16
],
"credentials": {
"httpHeaderAuth": {
"id": "Lf6835mjFnfNIqw6",
"name": "Header Auth account 2"
},
"httpBearerAuth": {
"id": "KFNalQ91U3mlnQks",
"name": "Bearer Auth account"
}
}
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "final-result",
"name": "verdict",
"value": "={{ $json.choices[0].message.content }}",
"type": "string"
},
{
"id": "model-a-ans",
"name": "answer_a",
"value": "={{ $node[\"Merge Answers1\"].json.answer_a }}",
"type": "string"
},
{
"id": "model-b-ans",
"name": "answer_b",
"value": "={{ $node[\"Merge Answers1\"].json.answer_b }}",
"type": "string"
},
{
"id": "model-c-ans",
"name": "answer_c",
"value": "={{ $node[\"Merge Answers1\"].json.answer_c }}",
"type": "string"
}
]
},
"options": {}
},
"id": "eae7f7bf-07fc-4250-b628-1a422cfbbe12",
"name": "Final Output1",
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
576,
16
]
}
],
"pinData": {},
"connections": {
"Set Question1": {
"main": [
[
{
"node": "Model A",
"type": "main",
"index": 0
},
{
"node": "Model B",
"type": "main",
"index": 0
},
{
"node": "Model C",
"type": "main",
"index": 0
}
]
]
},
"Model A": {
"main": [
[
{
"node": "Set Answer A1",
"type": "main",
"index": 0
}
]
]
},
"Model B": {
"main": [
[
{
"node": "Set Answer B1",
"type": "main",
"index": 0
}
]
]
},
"Model C": {
"main": [
[
{
"node": "Set Answer C1",
"type": "main",
"index": 0
}
]
]
},
"Set Answer A1": {
"main": [
[
{
"node": "Merge AB",
"type": "main",
"index": 0
}
]
]
},
"Set Answer B1": {
"main": [
[
{
"node": "Merge AB",
"type": "main",
"index": 1
}
]
]
},
"Set Answer C1": {
"main": [
[
{
"node": "Merge Answers1",
"type": "main",
"index": 1
}
]
]
},
"Merge AB": {
"main": [
[
{
"node": "Merge Answers1",
"type": "main",
"index": 0
}
]
]
},
"Merge Answers1": {
"main": [
[
{
"node": "AI Judge1",
"type": "main",
"index": 0
}
]
]
},
"AI Judge1": {
"main": [
[
{
"node": "Final Output1",
"type": "main",
"index": 0
}
]
]
}
},
"active": false,
"settings": {
"executionOrder": "v1",
"availableInMCP": false
},
"versionId": "ac74f20b-72a9-49a6-8200-fd08707946ec",
"meta": {
"instanceId": "2f42f1cdfcab2c6a7bbd5cec68912930ccc0107686e3a7211ddcc09504c524d9"
},
"id": "8a_wyeYhdVZSr42SS5Z1K",
"tags": []
}