---
title: "Whisky Tasting Agent:Base on critic RAG"
author: "Tony D"
date: "2025-11-05"
categories: [AI, API, tutorial]
image: "images/0.png"
format:
html:
code-fold: true
code-tools: true
code-copy: true
execute:
eval: false
warning: false
---
# Project Overview
The whisky tasting application is an advanced AI-powered web application that generates detailed, professional whisky tasting notes and recommendations. What makes this system special is its multi-agent architecture with specialized AI personalities, each trained on different whisky review sources and linguistic styles.
Live Demo(modelscope): [https://modelscope.cn/studios/ttflying/whisky_AI_tasting](https://modelscope.cn/studios/ttflying/whisky_AI_tasting)
Live Demo(shinyapp): [https://jcflyingco.shinyapps.io/ai-whisky-tasting/](https://jcflyingco.shinyapps.io/ai-whisky-tasting)
Github: [https://github.com/JCwinning/whisky_tasting](https://github.com/JCwinning/whisky_tasting)
::: {.panel-tabset}
## AI tasting note
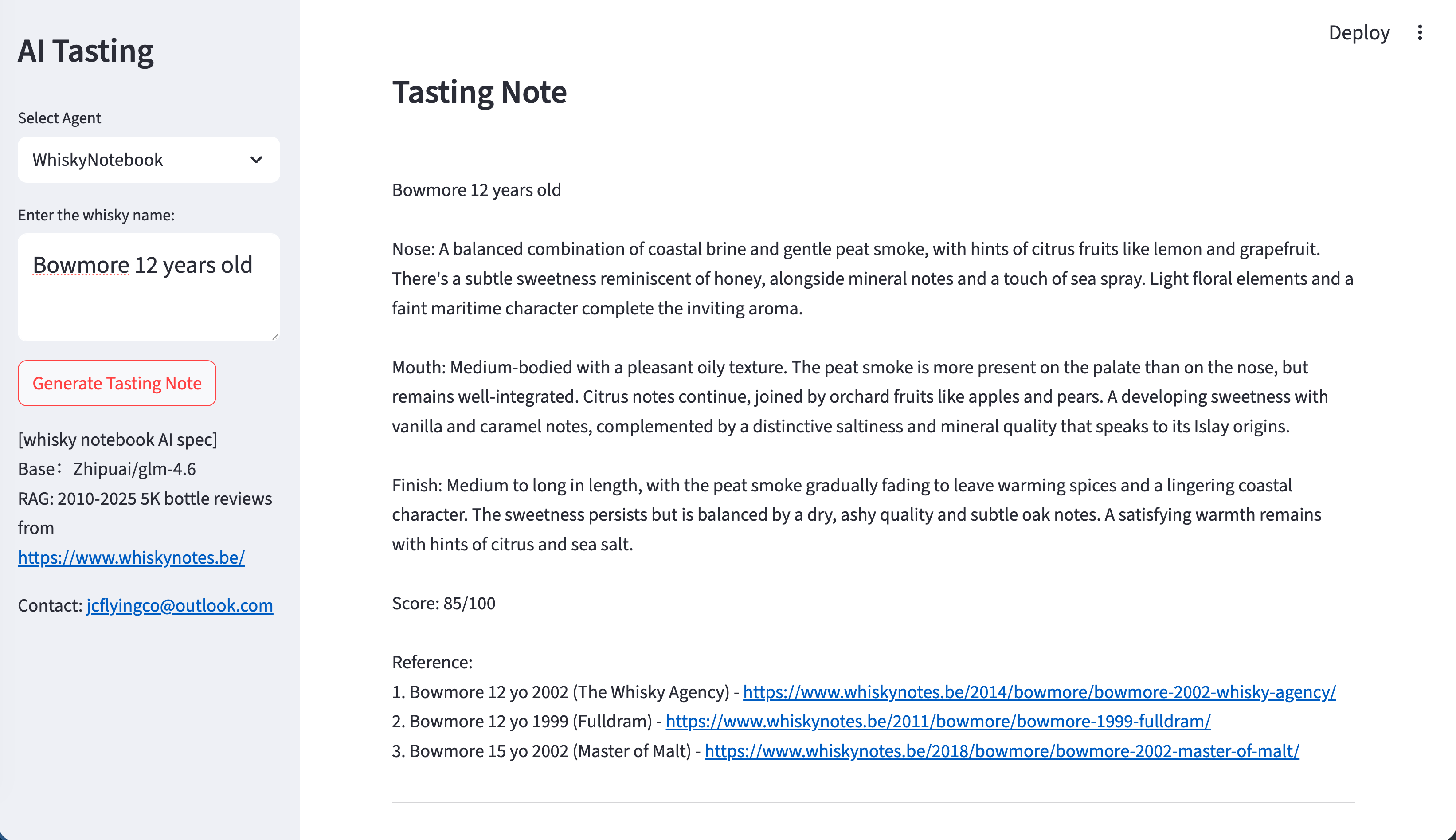{width="100%"}
## AI recommendation
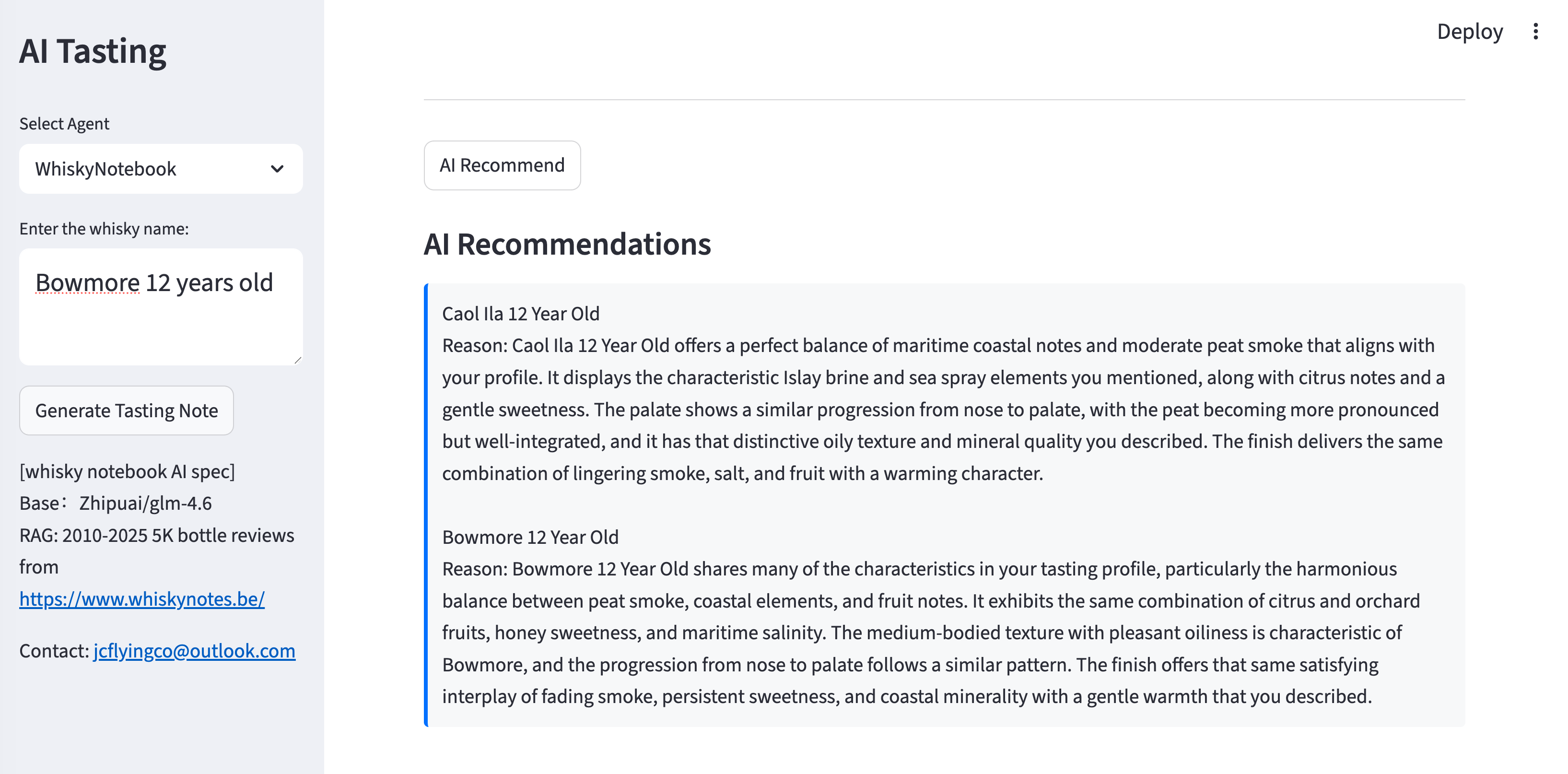{width="100%"}
## AI品鉴词
{width="100%"}
## AI推荐
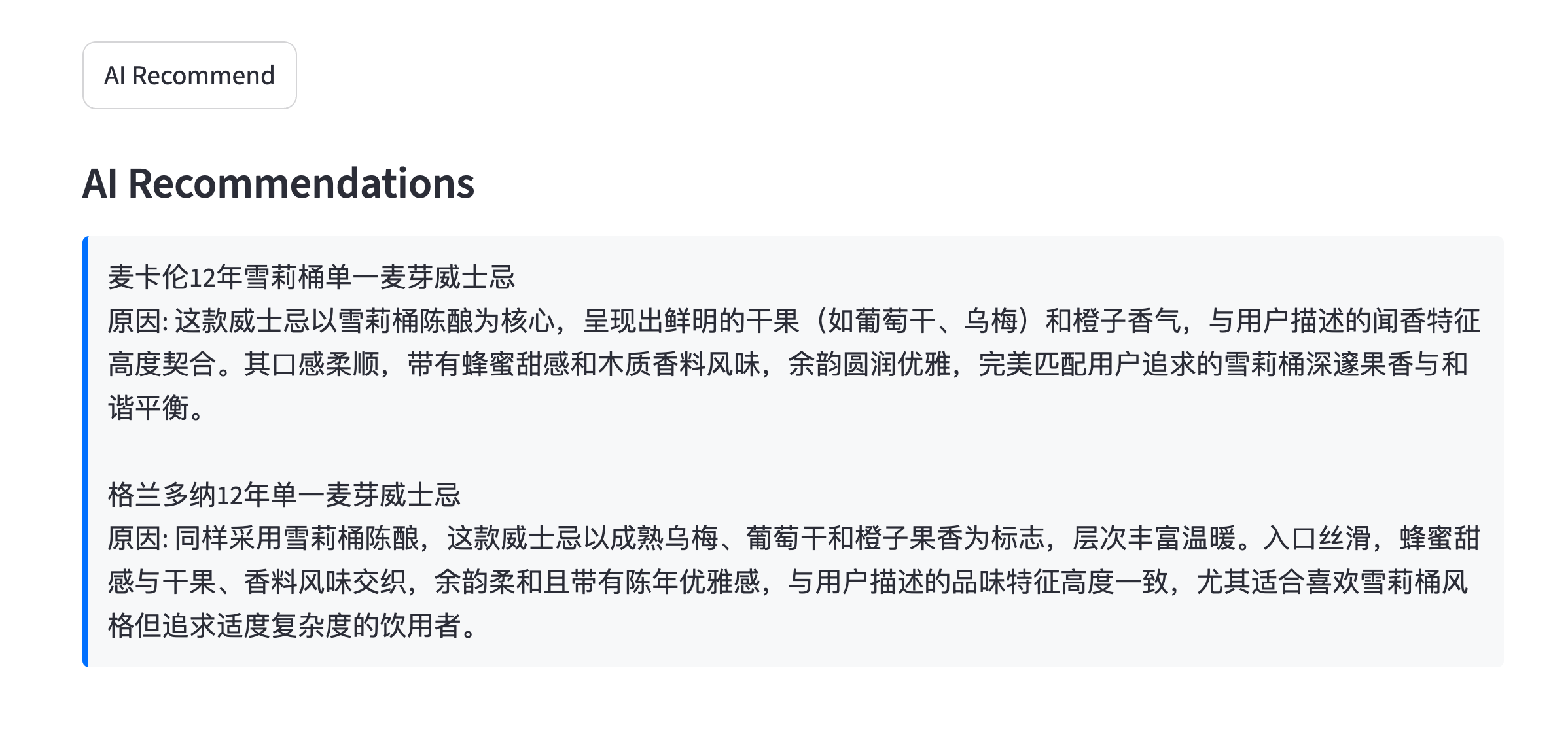{width="100%"}
:::
## Core Architecture
### Multi-Agent AI System
The application features three specialized AI agents, each with unique characteristics and data sources:
1. **DrunkTony (dt)** - Chinese-language agent specializing in Chinese whisky reviews
2. **WhiskyFunny (wf)** - English-language agent with data from whiskyfun.com
3. **WhiskyNotebook (wn)** - English-language agent with data from whiskynotes.be
### Technology Stack
- **Primary Language**: Python 3.13+
- **Web Framework**: Streamlit (primary) + Shiny for Python (alternative)
- **Database**: DuckDB (376MB, optimized for vector operations)
- **AI/ML**: OpenAI API, Vector embeddings, RAG system
- **Data Sources**: Web scraping with BeautifulSoup4
## Database Architecture
### Data Schema and Sources
The system uses DuckDB as its primary database, chosen for its excellent performance with vector operations:
```sql
-- Database structure
CREATE TABLE drinktony_embed (
full TEXT,
bottle_embedding FLOAT[1024] -- 1024-dimensional vectors
);
CREATE TABLE whiskyfun_embed (
full TEXT,
bottle_embedding FLOAT[1024]
);
CREATE TABLE whiskynote_embed (
full TEXT,
bottle_embedding FLOAT[1024]
);
```
### Data Collection Pipeline
```{python}
# Web scraping example from get_data_dt.py
def scrape_drinktony_reviews():
"""Scrape Chinese whisky reviews from drinktony.netlify.app"""
url = "https://drinktony.netlify.app/"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# Find all review links
post_links = [urljoin(url, a.get("href"))
for a in soup.select("a.quarto-grid-link")]
all_reviews = []
for post_url in post_links:
response = requests.get(post_url)
soup = BeautifulSoup(response.content, "html.parser")
# Extract review sections
review_sections = soup.select("section.level1")
for section in review_sections:
# Parse whisky name and review content
whisky_name = extract_whisky_name(section)
review_text = extract_review_text(section)
all_reviews.append({
'whisky': whisky_name,
'review': review_text
})
return all_reviews
```
## AI/ML Implementation
### Vector Embedding Technology
The application uses state-of-the-art embedding technology to convert text into high-dimensional vectors for semantic similarity search.
#### Embedding Model Details
**Model**: BAAI/bge-large-zh-v1.5
- **Dimensions**: 1024
- **Provider**: SiliconFlow API
- **Purpose**: Cross-lingual text understanding (works well for both Chinese and English)
#### Why BGE-Large-ZH?
1. **Cross-lingual Capability**: Excels at understanding both Chinese and English whisky terminology
2. **High Performance**: Superior semantic understanding compared to generic embeddings
3. **Efficient Size**: 1024 dimensions balance between performance and storage efficiency
4. **API Access**: Stable service via SiliconFlow
#### Embedding Process
The application uses BGE-Large-ZH-v1.5 model for generating embeddings:
```{python}
def get_embedding(text: str, api_key: str):
"""Generate text embeddings using SiliconFlow API"""
client = OpenAI(
api_key=api_key,
base_url="https://api.siliconflow.cn/v1"
)
response = client.embeddings.create(
model="BAAI/bge-large-zh-v1.5",
input=[text]
)
return np.array(response.data[0].embedding)
def cosine_similarity(v1, v2):
"""Calculate cosine similarity between two vectors"""
if v1 is None or v2 is None:
return 0
return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))
```
### RAG System Architecture
The Retrieval-Augmented Generation (RAG) system is the core innovation of this application. Let's explore its components in detail.
### RAG Workflow
The Retrieval-Augmented Generation process follows these steps:
```mermaid
%%| fig-cap: "RAG Workflow for Whisky Tasting"
flowchart TD
A[User Input<br/>Whisky Name] --> B[Generate Embedding]
B --> C[Vector Similarity Search<br/>in DuckDB]
C --> D[Retrieve Top 10<br/>Similar Reviews]
D --> E[Format Context for LLM]
E --> F[Generate Tasting Notes<br/>with Primary LLM]
F --> G[Generate Recommendations<br/>with Secondary LLM]
G --> H[Display Results<br/>with Formatting]
C --> I[Databases]
I --> J[drinktony_embed<br/>1.2K Chinese reviews]
I --> K[whiskyfun_embed<br/>20K English reviews]
I --> L[whiskynote_embed<br/>5K English reviews]
```
### Similarity Search Implementation
```{python}
def find_similar_chunks(
query_embedding,
db_path,
table_name,
text_col,
embedding_col,
top_n=10,
):
"""Find most similar chunks in database using cosine similarity"""
try:
with duckdb.connect(database=db_path, read_only=True) as con:
df = con.execute(
f'SELECT "{text_col}", "{embedding_col}" FROM "{table_name}"'
).fetchdf()
# Calculate similarities
similarities = []
for _, row in df.iterrows():
text = row[text_col]
embedding = np.array(row[embedding_col])
similarity = cosine_similarity(query_embedding, embedding)
similarities.append((text, similarity))
# Sort by similarity and return top N
similarities.sort(key=lambda x: x[1], reverse=True)
return similarities[:top_n]
except Exception as e:
print(f"Error searching similar chunks: {e}")
return []
```
## Specialized Agent Implementation
### DrunkTony (Chinese Agent)
```{python}
def run_conversation(query, api_key, model):
"""Generate whisky tasting notes in Chinese format"""
# Step 1: Generate embedding and find similar reviews
query_embedding = get_embedding(query, api_key)
similar_reviews = find_similar_chunks(
query_embedding=query_embedding,
db_path="data/whisky_database.duckdb",
table_name="drinktony_embed",
text_col="full",
embedding_col="bottle_embedding"
)
# Step 2: Format context for LLM
context = "\n---\n".join([review[0] for review in similar_reviews])
# Step 3: Generate tasting notes
prompt = f"""作为威士忌专家,基于以下威士忌品鉴笔记,为"{query}"生成专业的品鉴报告:
参考品鉴笔记:
{context}
请按以下格式输出:
{query}
闻香: [详细描述]
品味: [详细描述]
打分: [90-100分]
"""
response = llm_client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "你是一位专业的威士忌品鉴师,擅长生成详细准确的品鉴笔记。"},
{"role": "user", "content": prompt}
],
temperature=0.7,
max_tokens=1000
)
return response.choices[0].message.content
```
### WhiskyFunny (English Agent)
```{python}
def run_conversation(query, api_key, model):
"""Generate whisky tasting notes in English format"""
query_embedding = get_embedding(query, api_key)
similar_reviews = find_similar_chunks(
query_embedding=query_embedding,
db_path="data/whisky_database.duckdb",
table_name="whiskyfun_embed",
text_col="full",
embedding_col="bottle_embedding"
)
context = "\n---\n".join([review[0] for review in similar_reviews])
prompt = f"""As a whisky expert, generate professional tasting notes for "{query}" based on these reference reviews:
Reference reviews:
{context}
Please output in this format:
Colour: [detailed description]
Nose: [detailed aroma description]
Mouth: [detailed taste description]
Finish: [detailed finish description]
Comments: [overall impression]
SGP: xxx - xx points
"""
response = llm_client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a professional whisky taster specializing in detailed sensory analysis."},
{"role": "user", "content": prompt}
],
temperature=0.7,
max_tokens=1200
)
return response.choices[0].message.content
```
## Recommendation Engine
### Dual-LLM Recommendation System
The application uses a separate LLM for generating whisky recommendations:
```{python}
def recommend_whiskies_by_profile(tasting_notes, api_key, model):
"""Generate whisky recommendations based on tasting profile"""
prompt = f"""Based on these tasting notes, recommend 2 similar whiskies that the user might enjoy:
{Tasting Notes:}
{tasting_notes}
Please provide:
1. Whisky name with brief description
2. Why it matches the user's preference
3. Price range and availability
Format each recommendation as:
**Recommendation [1/2]:** [Whisky Name]
**Why it matches:** [detailed reasoning]
**Details:** [price, availability, tasting profile]
"""
response = recommendation_client.chat.completions.create(
model=model, # Different model for recommendations
messages=[
{"role": "system", "content": "You are a whisky recommendation expert with deep knowledge of global whisky brands and profiles."},
{"role": "user", "content": prompt}
],
temperature=0.8,
max_tokens=800
)
return response.choices[0].message.content
```
## User Interface Design
### Streamlit Implementation
```{python}
# Main application interface
def main():
st.set_page_config(
page_title="AI Whisky Tasting System",
page_icon="🥃",
layout="wide"
)
# Sidebar for agent selection
with st.sidebar:
st.header("🥃 Whisky AI Tasting")
# Agent selection
agent_type = st.selectbox(
"Select Tasting Agent:",
["DrunkTony (中文)", "WhiskyFunny (English)", "WhiskyNotebook (English)"],
help="Each agent has different personality and data sources"
)
# Model selection
model_options = get_model_options(agent_type)
selected_model = st.selectbox("Model:", model_options)
# Main content area
st.header("Professional Whisky Tasting Notes Generator")
# Input section
col1, col2 = st.columns([2, 1])
with col1:
whisky_name = st.text_input(
"Enter whisky name:",
placeholder="e.g., Macallan 18 Year Old",
help="Enter the full whisky name including age and cask type"
)
with col2:
st.write("") # Spacer
generate_btn = st.button("🍷 Generate Tasting Notes", type="primary")
recommend_btn = st.button("🎯 Get Recommendations")
# Output sections
if generate_btn:
if not whisky_name:
st.error("Please enter a whisky name")
else:
with st.spinner("Analyzing whisky..."):
tasting_notes = generate_tasting_notes(whisky_name, agent_type, selected_model)
st.markdown("### 🥃 Tasting Notes")
st.markdown(tasting_notes)
if recommend_btn:
with st.spinner("Finding recommendations..."):
recommendations = get_recommendations(tasting_notes, agent_type)
st.markdown("### 🎯 Personalized Recommendations")
st.markdown(recommendations)
```
## Rate Limiting and Cost Management
### API Usage Control
```{python}
# Rate limiting implementation
RATE_LIMIT_FILE = "rate_limit.json"
MAX_RUNS_PER_DAY = 80
def get_rate_limit_data():
"""Get current usage data"""
try:
with open(RATE_LIMIT_FILE, "r") as f:
data = json.load(f)
# Ensure keys exist
if "date" not in data or "count" not in data:
return {"date": str(datetime.date.today()), "count": 0}
return data
except (FileNotFoundError, json.JSONDecodeError):
return {"date": str(datetime.date.today()), "count": 0}
def check_rate_limit():
"""Check if user has exceeded daily limit"""
data = get_rate_limit_data()
today = str(datetime.date.today())
if data["date"] != today:
# Reset counter for new day
return {"date": today, "count": 0, "can_run": True}
if data["count"] >= MAX_RUNS_PER_DAY:
return {"date": today, "count": data["count"], "can_run": False}
return {"date": today, "count": data["count"], "can_run": True}
```
## Performance Optimization
### Vector Database Performance
```{python}
# Optimized similarity search with batching
def batch_similarity_search(query_embedding, db_path, table_name, batch_size=1000):
"""Optimized similarity search with batching for large datasets"""
with duckdb.connect(database=db_path, read_only=True) as con:
# Get total row count
total_rows = con.execute(f"SELECT COUNT(*) FROM {table_name}").fetchone()[0]
all_similarities = []
# Process in batches to manage memory
for offset in range(0, total_rows, batch_size):
batch_df = con.execute(
f'SELECT full, bottle_embedding FROM {table_name} LIMIT {batch_size} OFFSET {offset}'
).fetchdf()
# Calculate similarities for batch
for _, row in batch_df.iterrows():
embedding = np.array(row['bottle_embedding'])
similarity = cosine_similarity(query_embedding, embedding)
all_similarities.append((row['full'], similarity))
# Sort and return top results
all_similarities.sort(key=lambda x: x[1], reverse=True)
return all_similarities[:10]
```
## Deployment and Configuration
### Environment Setup
```bash
# Environment variables in .env file
SILICONFLOW_API_KEY=your_siliconflow_key
MODELSCOPE_API_KEY=your_modelscope_key
GEMINI_API_KEY=your_gemini_key # Optional
# Database initialization
python -c "
import duckdb
conn = duckdb.connect('data/whisky_database.duckdb')
# Create tables with vector support
"
```
### Shiny for Python Alternative
```{python}
# Alternative UI implementation using Shiny
from shiny import App, ui, render, reactive, req
app_ui = ui.page_fluid(
ui.h2("🥃 AI Whisky Tasting System"),
ui.layout_sidebar(
ui.sidebar(
ui.input_select("agent", "Select Agent:", [
"DrunkTony (中文)", "WhiskyFunny (English)", "WhiskyNotebook (English)"
]),
ui.input_text("whisky_name", "Whisky Name:", ""),
ui.input_action_button("generate", "Generate Notes")
),
ui.output_text_verbatim("tasting_notes"),
ui.output_text_verbatim("recommendations")
)
)
def server(input, output, session):
@output
@render.text
def tasting_notes():
req(input.generate())
# Generate tasting notes logic
return generate_tasting_notes(input.whisky_name(), input.agent())
app = App(app_ui, server)
```
## Technical Achievements
### Key Innovations
1. **Multi-Agent Architecture**: Different AI personalities and data sources
2. **RAG Implementation**: Retrieval-augmented generation with real whisky reviews
3. **Vector Database**: Efficient similarity search with 376MB database
4. **Bilingual Support**: Chinese and English language agents
5. **Cost Management**: Built-in rate limiting and API optimization
6. **Professional Tasting Formats**: Industry-standard note structures
### Performance Metrics
| Metric | Value |
|--------|-------|
| Database Size | 376MB (26K+ reviews) |
| Embedding Dimension | 1024 |
| Search Latency | <2 seconds |
| Daily Request Limit | 80 requests |
| Support Languages | 2 (EN/ZH) |
| Data Sources | 3 (drinktony, whiskyfun, whiskynotes) |
## Future Enhancements
Potential improvements for next versions:
1. **Advanced Similarity Algorithms**: Implement hybrid search with text + metadata
2. **User Personalization**: Learn from user preferences over time
3. **Mobile App**: Native iOS/Android applications
4. **Real-time Data Updates**: Automated web scraping pipeline
5. **Tasting Profile Analysis**: Generate user taste profiles from preferences
6. **Social Features**: Share tasting notes and recommendations with community
## Conclusion
This whisky tasting application demonstrates the power of combining RAG technology with specialized AI agents to create a sophisticated domain-specific system. The project showcases:
- **Advanced AI Architecture**: Multi-agent system with different personalities
- **Data Engineering**: Large-scale vector database management
- **Professional Knowledge**: Industry-standard tasting note formats
- **User Experience**: Clean, intuitive interfaces across platforms
- **Cost Efficiency**: Smart rate limiting and optimization
Whether you're a whisky enthusiast, AI developer, or data scientist, this project provides an excellent example of building production-grade AI applications that combine real-world data with advanced machine learning techniques.
---
**Technology Stack**: Python, Streamlit, DuckDB, OpenAI API, Vector Embeddings
**Database**: 26K+ real whisky reviews across 3 specialized sources



