LLM Summary System: A Multi-Platform AI Summarization Tool
Introduction
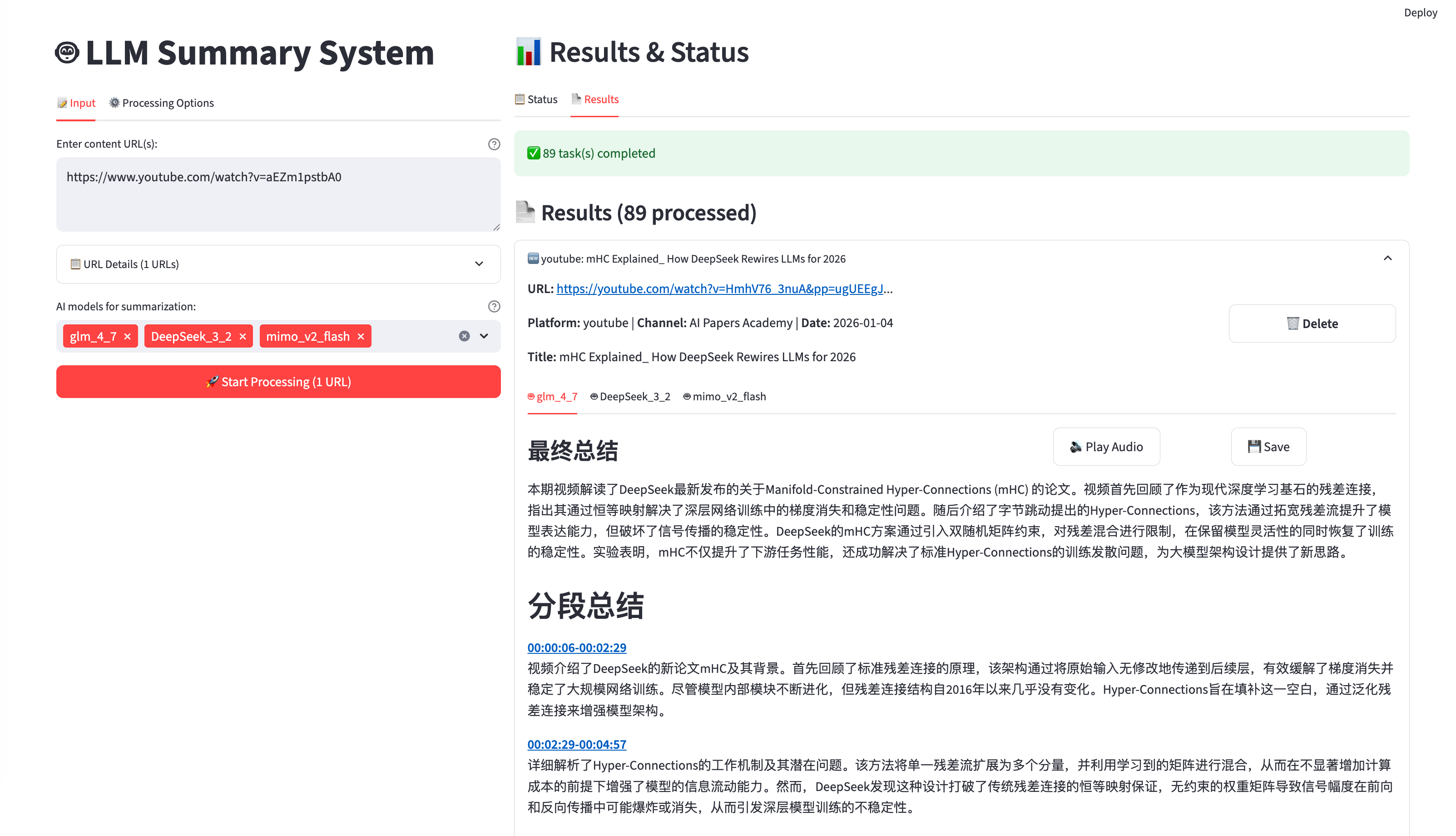
In the era of information explosion, keeping up with content across multiple platforms like YouTube, Bilibili, Spotify, and Xiaohongshu can be overwhelming. The LLM Summary System is a powerful, unified tool designed to solve this by automating the process of downloading, transcribing, and summarizing content using state-of-the-art Large Language Models (LLMs).
This project provides a seamless experience for converting long-form audio/video content into concise, actionable summaries.
Key Features
The system is packed with features that make it a robust choice for content consumption:
- Multi-Platform Support: Unified interface for YouTube, Bilibili, Spotify, Xiaohongshu, and Xiaoyuzhou FM.
- Intelligent Processing: Automatic chunking for large files and transcripts to handle long-form content (up to 2M tokens).
- High-Quality Transcription: Uses MLX Whisper (optimized for Apple Silicon) with an OpenAI Whisper fallback.
- Advanced Summarization: Support for 15+ LLM models (including Qwen, GLM, DeepSeek, GPT-4, Gemini, and Grok).
- Text-to-Speech (TTS): Convert summaries back to audio using Google Cloud TTS, Qwen, or Gemini.
- Search Integration: Automatically finds related reading materials using AI-extracted keywords.
- Real-time Progress Tracking: A user-friendly Streamlit web interface with live updates.
Architecture Overview
The system follows a streamlined pipeline:
graph LR
A[URL Input] --> B[Platform Detection]
B --> C[Content Download]
C --> D[Audio Extraction]
D --> E[Transcription - Whisper]
E --> F[AI Summarization]
F --> G[TTS Generation]
G --> H[File Output + Web Display]Core Components
app.py: The main Streamlit web interface handle concurrent URL submission and dynamic queuing.download.py: A unified downloader with comprehensive retry logic for all supported platforms.process.py: Handles audio transcription and AI summarization with intelligent chunking.config.py: Manages LLM model configurations and environment variables.tts.py: Multi-provider text-to-speech with hash-based caching.
Advanced Intelligence
What sets this system apart is its handling of complex tasks:
Intelligent Chunking
To prevent RAM exhaustion and handle extremely long content: - Audio: Automatically splits files longer than 60 minutes for transcription. - Text: Transcripts exceeding 240K characters are split into 100K character chunks.
Search Integration
After generating a summary, the system extracts key terms and searches for supplemental materials via DuckDuckGo (or Baidu as a fallback). This ensures you get a well-rounded understanding of the topic.
Getting Started
The easiest way to run the system is via the Web Interface:
Clone the repository:
git clone https://github.com/JCwinning/llm_summary.git cd llm_summaryConfigure your environment: Create a
.envfile with your API keys (OpenAI, DashScope, etc.).Install dependencies:
pip install -r requirements.txtRun the app:
streamlit run app.py
Conclusion
The LLM Summary System is more than just a downloader; it’s a personalized AI research assistant. Whether you’re a student, researcher, or just someone who wants to stay informed, this tool can significantly boost your productivity by distilling hours of content into minutes of reading.
Check out the full source code and contribute on GitHub.