Code
library(ggplot2)
library(tidyverse)
library(openxlsx)
library(readxl)
library(plotly)
library(GGally)
library(corrplot)Comparing Personal Ratings with Whiskybase Community Ratings
This case study compares personal whisky ratings with community ratings from Whiskybase, revealing significant differences and strong correlations. Key findings include: community ratings are approximately 2 points higher on average (p < 0.001), with a strong positive correlation (ρ = 0.68) between personal and community ratings. Both rating types show moderate to strong positive correlations with whisky age (personal: ρ = 0.41, community: ρ = 0.57). All variables deviate from normality, necessitating non-parametric analyses.
This document presents a statistical analysis of whisky ratings, comparing a personal rating dataset (my_rating) with a community-based rating from Whiskybase (wb_rating). Whisky ratings typically use scales from 1-100 or similar, with Whiskybase aggregating user-submitted scores. Personal ratings may reflect individual preferences and tasting conditions, while community ratings represent broader consensus but could be influenced by popularity bias or review volume.
The analysis aims to answer several key questions:
We will use various statistical tests, including the Shapiro-Wilk test for normality, the paired t-test, the Wilcoxon signed-rank test, and Spearman’s correlation test, to draw meaningful conclusions from the data.
First, we load the necessary R libraries for data manipulation, visualization, and reading Excel files.
library(ggplot2)
library(tidyverse)
library(openxlsx)
library(readxl)
library(plotly)
library(GGally)
library(corrplot)We read the data from an Excel file, create new columns for rounded ratings and the difference between ratings, and filter out entries with missing age information.
data001 <- read_excel('../data/Ratings.xlsx')
data001 <- data001 %>%
mutate(
wb_rating = round(rating),
diff = wb_rating - my_rating,
age = as.numeric(stated_age)
)
# Create a second dataset for age-related analysis, filtering out NAs
data002 <- data001 %>%
filter(!is.na(age))
# Glimpse the structure of the datasets
glimpse(data001)Rows: 827
Columns: 14
$ whisky <chr> "Bowmore 1965 Islay Pure Malt", "Highland Park 40-y…
$ stated_age <chr> "-", "40", "28", "21", "24", "20", "16", "18", "29",…
$ strength <chr> "50.0 % Vol.", "48.3 % Vol.", "51.5 % Vol.", "56.9 %…
$ size <chr> "750 ml", "700 ml", "500 ml", "700 ml", "700 ml", "7…
$ number_of_bottles <chr> "-", "-", "912", "-", "-", "-", "-", "-", "-", "199"…
$ casknumber <chr> "-", "-", "400295", "-", "-", "-", "-", "-", "10568"…
$ votes <dbl> 97, 233, 44, 269, 253, 24, 20, 48, 9, 24, 63, 65, 11…
$ rating <dbl> 94.13, 92.73, 91.67, 91.75, 92.11, 91.50, 91.29, 88.…
$ my_rating <dbl> 96, 95, 95, 94, 94, 94, 94, 94, 94, 93, 93, 93, 93, …
$ bottle_link <chr> "https://www.whiskybase.com/whiskies/whisky/207894/b…
$ pic_link <chr> "https://static.whiskybase.com/storage/whiskies/2/0/…
$ wb_rating <dbl> 94, 93, 92, 92, 92, 92, 91, 89, 91, 90, 92, 94, 93, …
$ diff <dbl> -2, -2, -3, -2, -2, -2, -3, -5, -3, -3, -1, 1, 0, 0,…
$ age <dbl> NA, 40, 28, 21, 24, 20, 16, 18, 29, 28, 7, 30, NA, N…glimpse(data002)Rows: 652
Columns: 14
$ whisky <chr> "Highland Park 40-year-old", "Redbreast 28-year-old …
$ stated_age <chr> "40", "28", "21", "24", "20", "16", "18", "29", "28"…
$ strength <chr> "48.3 % Vol.", "51.5 % Vol.", "56.9 % Vol.", "61.3 %…
$ size <chr> "700 ml", "500 ml", "700 ml", "700 ml", "750 ml", "7…
$ number_of_bottles <chr> "-", "912", "-", "-", "-", "-", "-", "-", "199", "-"…
$ casknumber <chr> "-", "400295", "-", "-", "-", "-", "-", "10568", "72…
$ votes <dbl> 233, 44, 269, 253, 24, 20, 48, 9, 24, 63, 65, 62, 13…
$ rating <dbl> 92.73, 91.67, 91.75, 92.11, 91.50, 91.29, 88.98, 90.…
$ my_rating <dbl> 95, 95, 94, 94, 94, 94, 94, 94, 93, 93, 93, 93, 93, …
$ bottle_link <chr> "https://www.whiskybase.com/whiskies/whisky/1706/hig…
$ pic_link <chr> "https://static.whiskybase.com/storage/whiskies/1/7/…
$ wb_rating <dbl> 93, 92, 92, 92, 92, 91, 89, 91, 90, 92, 94, 91, 91, …
$ diff <dbl> -2, -3, -2, -2, -2, -3, -5, -3, -3, -1, 1, -2, -2, -…
$ age <dbl> 40, 28, 21, 24, 20, 16, 18, 29, 28, 7, 30, 35, 27, 2…The dataset contains whisky ratings with the following characteristics:
cat("Total observations:", nrow(data001), "\n")Total observations: 827 cat("Observations with age data:", nrow(data002), "\n")Observations with age data: 652 cat(
"My rating range:",
min(data001$my_rating),
"to",
max(data001$my_rating),
"\n"
)My rating range: 65 to 96 cat(
"Whiskybase rating range:",
min(data001$wb_rating),
"to",
max(data001$wb_rating),
"\n"
)Whiskybase rating range: 68 to 94 cat(
"Age range (years):",
min(data002$age, na.rm = TRUE),
"to",
max(data002$age, na.rm = TRUE),
"\n"
)Age range (years): 3 to 60 summary(data001) whisky stated_age strength size
Length:827 Length:827 Length:827 Length:827
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
number_of_bottles casknumber votes rating
Length:827 Length:827 Min. : 1.0 Min. :68.45
Class :character Class :character 1st Qu.: 14.0 1st Qu.:87.27
Mode :character Mode :character Median : 34.0 Median :88.89
Mean : 156.9 Mean :88.44
3rd Qu.: 103.5 3rd Qu.:90.00
Max. :5439.0 Max. :94.30
my_rating bottle_link pic_link wb_rating
Min. :65.00 Length:827 Length:827 Min. :68.00
1st Qu.:84.00 Class :character Class :character 1st Qu.:87.00
Median :87.00 Mode :character Mode :character Median :89.00
Mean :86.46 Mean :88.44
3rd Qu.:89.00 3rd Qu.:90.00
Max. :96.00 Max. :94.00
diff age
Min. :-9.000 Min. : 3.00
1st Qu.: 0.000 1st Qu.:15.00
Median : 2.000 Median :23.00
Mean : 1.981 Mean :21.82
3rd Qu.: 3.000 3rd Qu.:27.00
Max. :17.000 Max. :60.00
NA's :175 # Histograms
ggplot(data001, aes(x = my_rating)) +
geom_histogram(binwidth = 1, fill = "blue", alpha = 0.7) +
ggtitle("Distribution of My Ratings")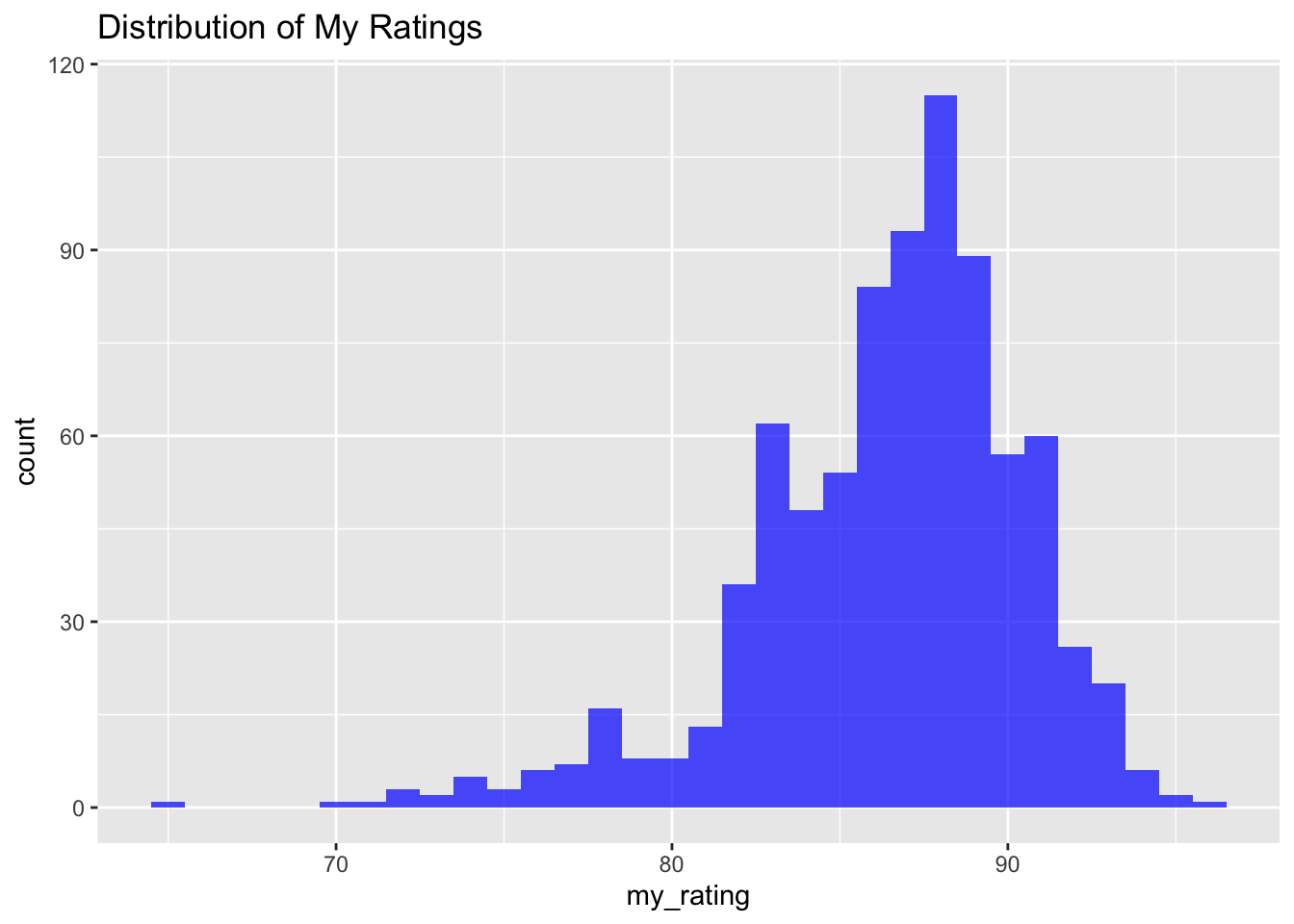
ggplot(data001, aes(x = wb_rating)) +
geom_histogram(binwidth = 1, fill = "red", alpha = 0.7) +
ggtitle("Distribution of Whiskybase Ratings")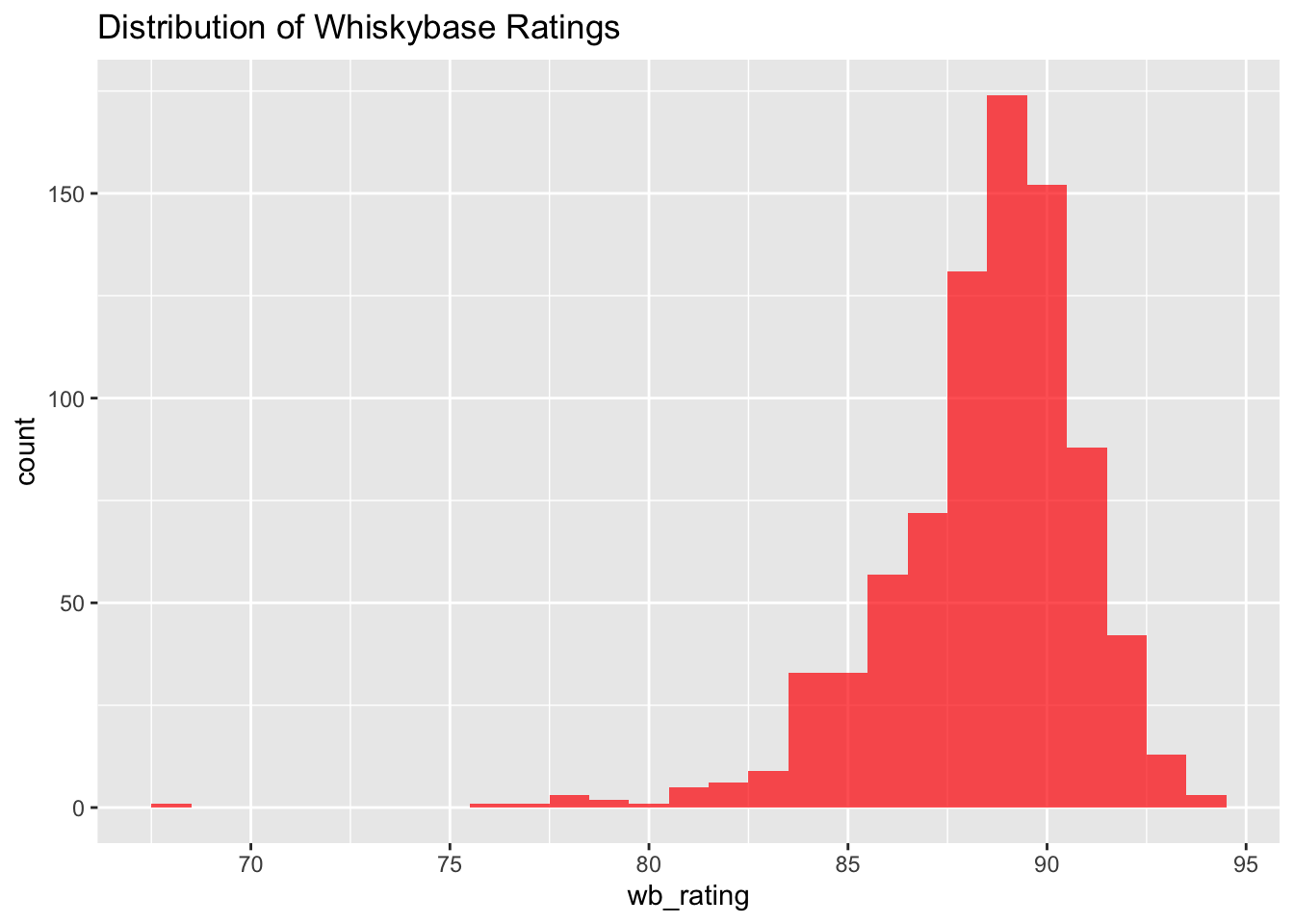
# Boxplots
ggplot(data001, aes(y = my_rating)) +
geom_boxplot(fill = "blue", alpha = 0.7) +
ggtitle("Boxplot of My Ratings")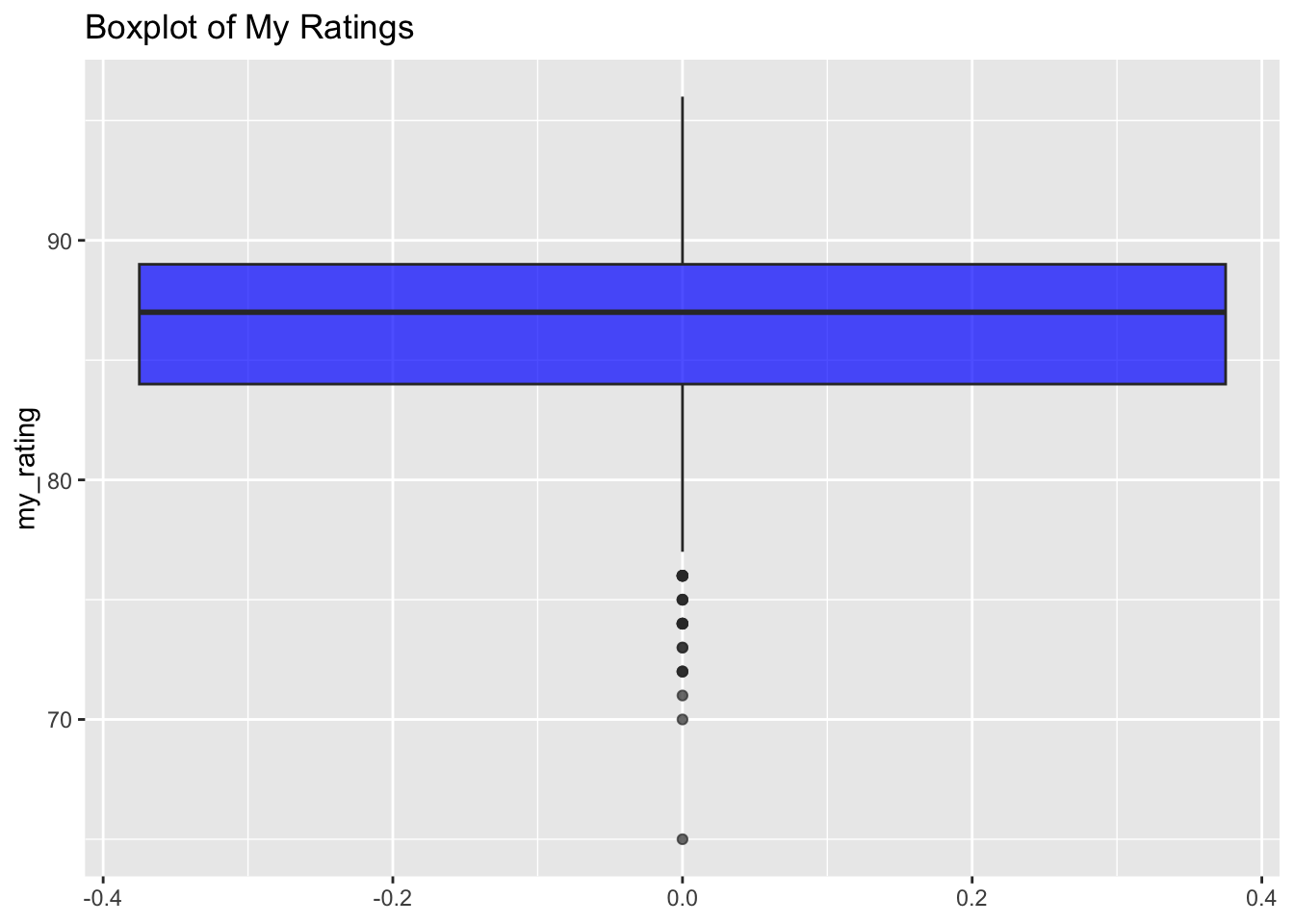
ggplot(data001, aes(y = wb_rating)) +
geom_boxplot(fill = "red", alpha = 0.7) +
ggtitle("Boxplot of Whiskybase Ratings")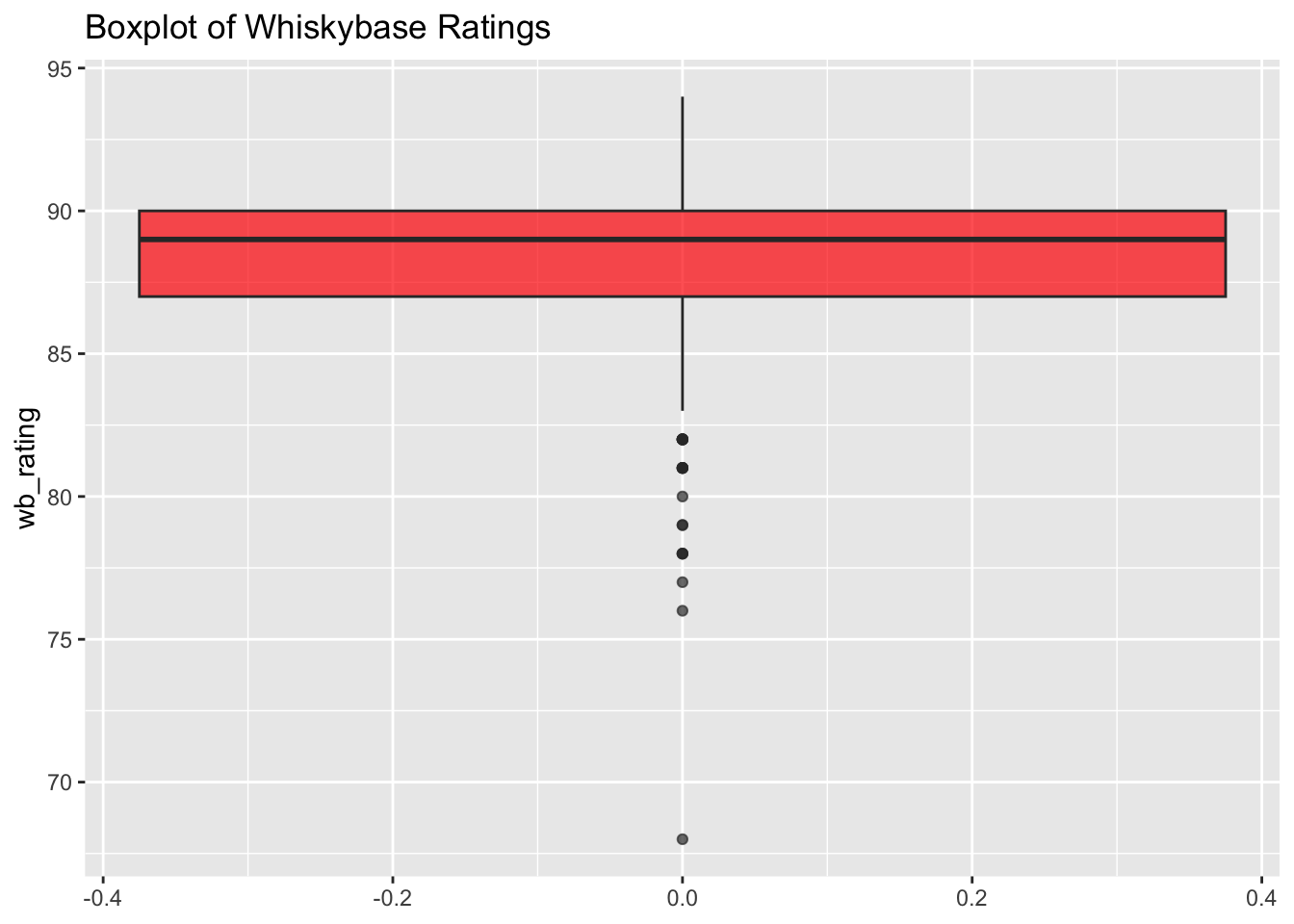
ggpairs(data001 %>% select(my_rating, wb_rating, diff))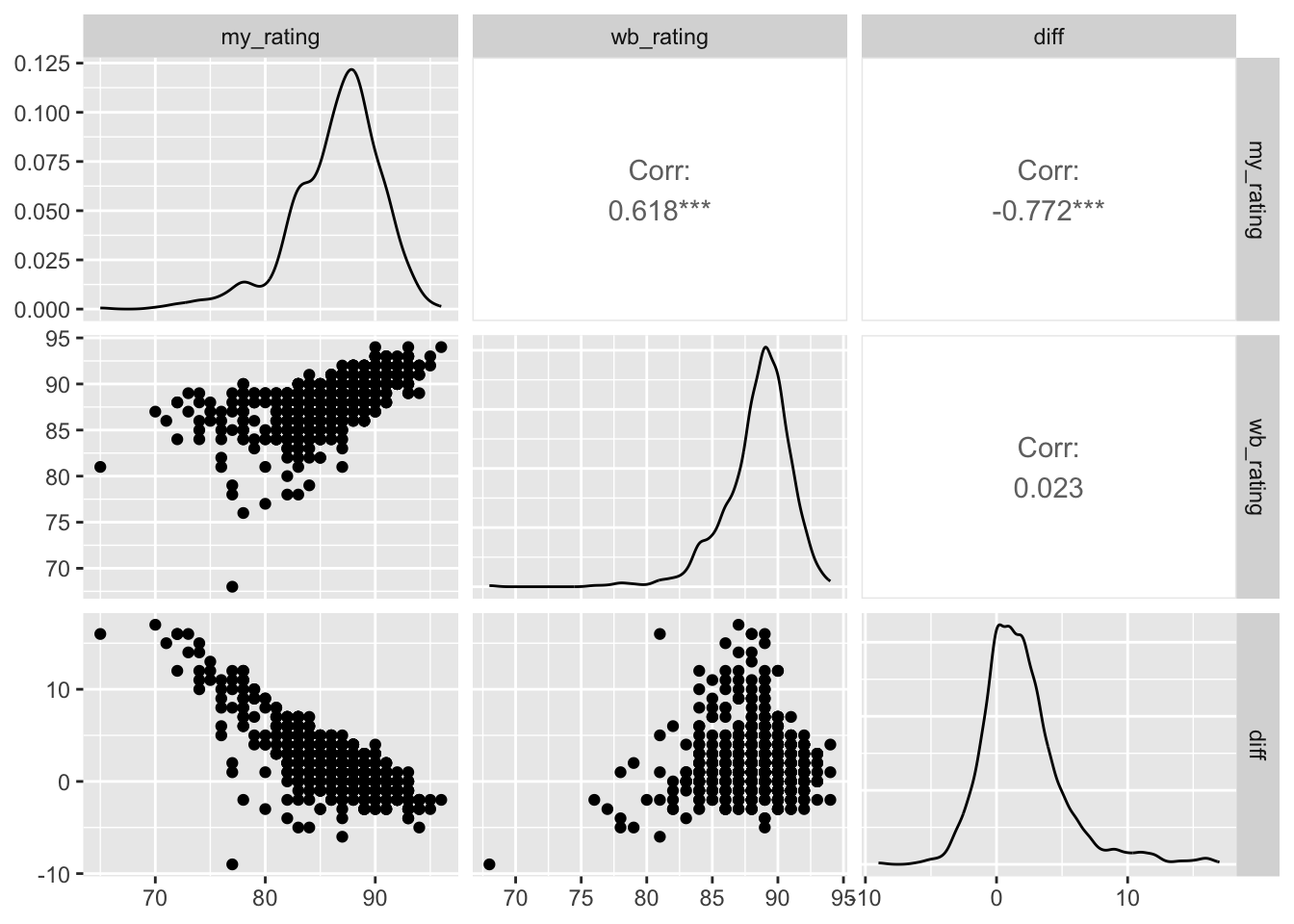
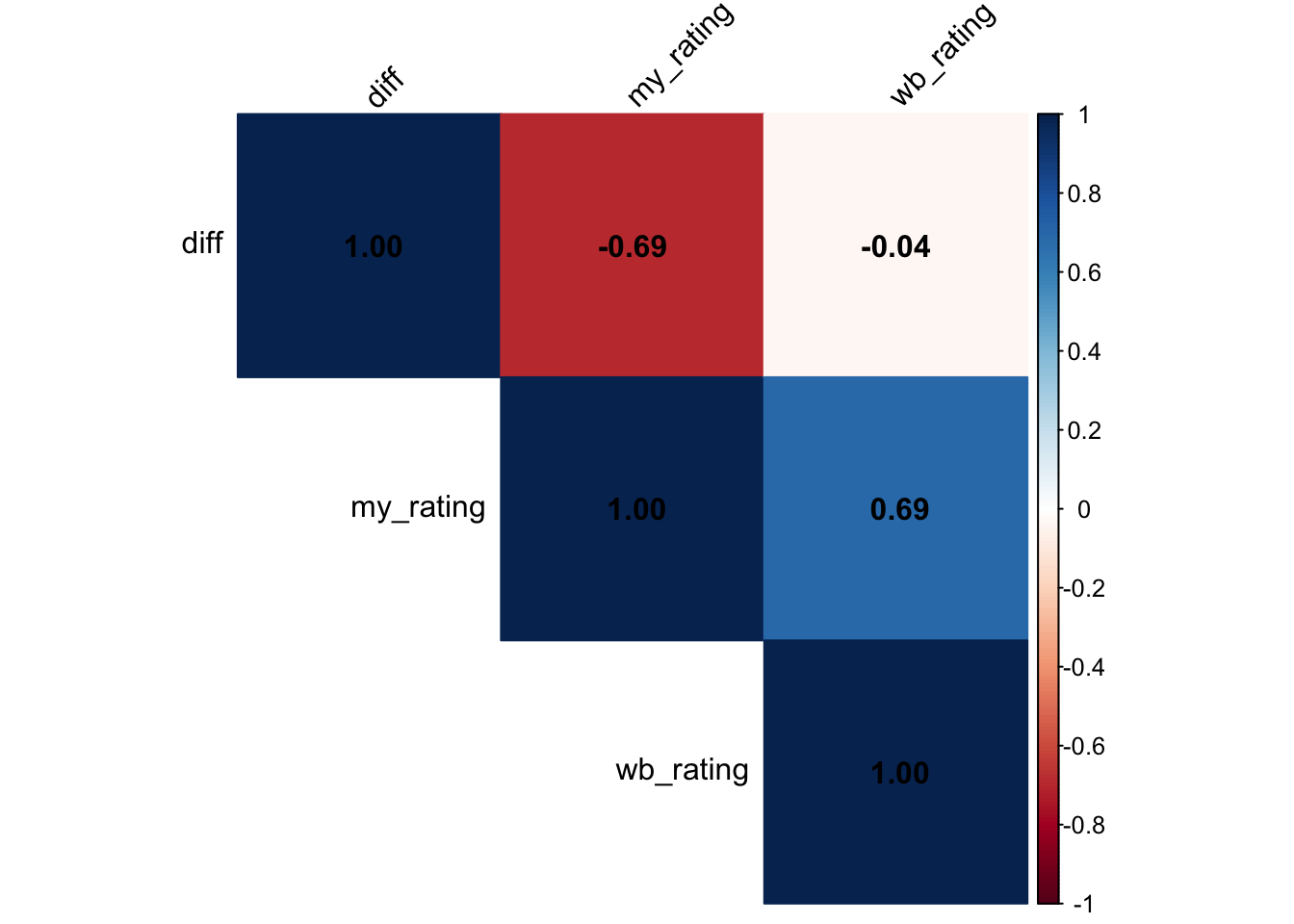
cor_matrix <- cor(
data001 %>% select(my_rating, wb_rating, diff),
method = "spearman"
)
corrplot(
cor_matrix,
method = "color",
type = "upper",
order = "hclust",
addCoef.col = "black",
tl.col = "black",
tl.srt = 45
)
Before performing parametric tests like the t-test, it’s crucial to check if the data is normally distributed. We use the Shapiro-Wilk test for this purpose.
Null Hypothesis (H0): The data is normally distributed. Alternative Hypothesis (H1): The data is not normally distributed.
If the p-value is less than 0.05, we reject the null hypothesis.
my_rating)shapiro.test(data001$my_rating)
Shapiro-Wilk normality test
data: data001$my_rating
W = 0.94121, p-value < 2.2e-16qqnorm(data001$my_rating)
qqline(data001$my_rating, col = "red")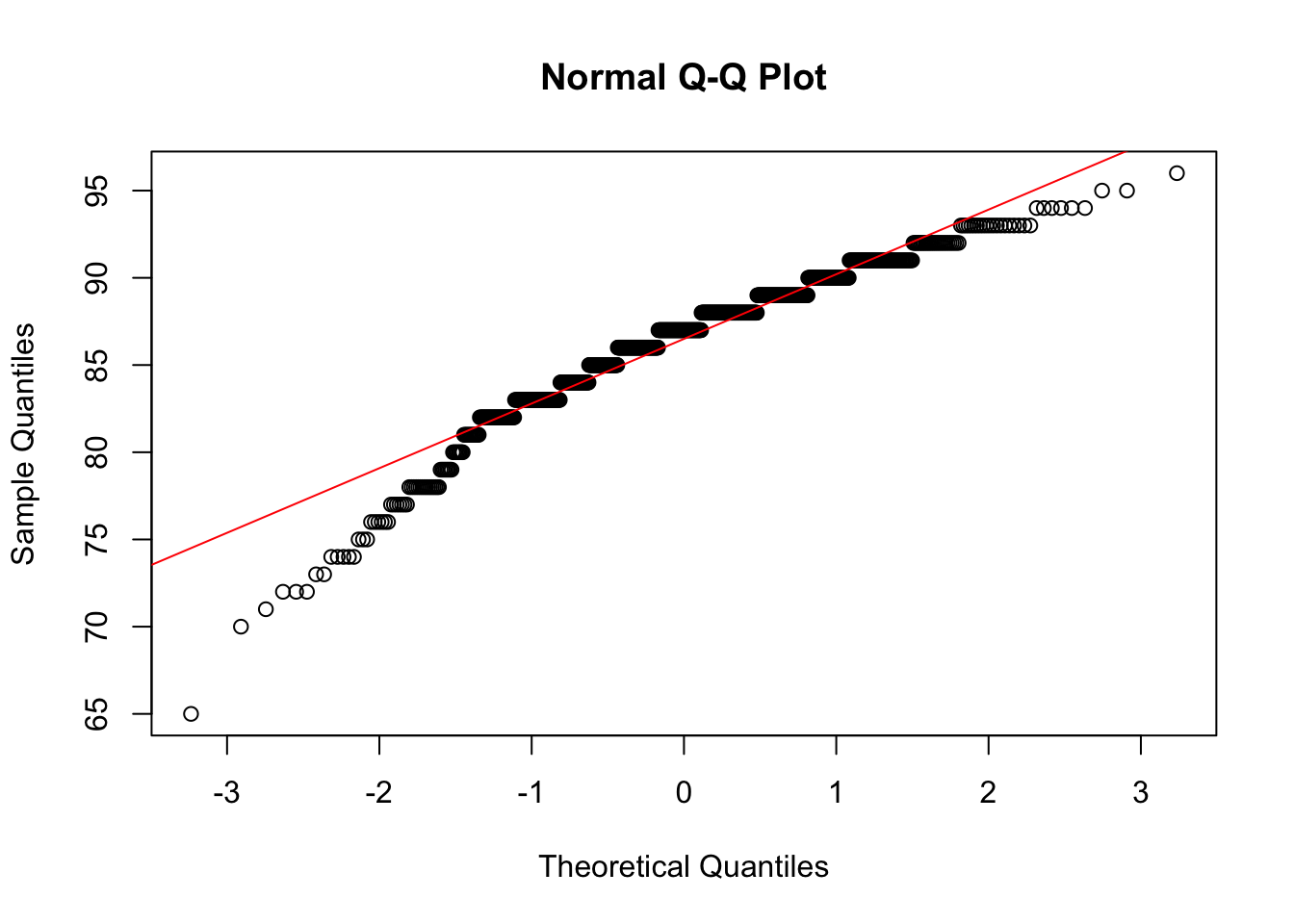
Result: The p-value is much less than 0.05, so we reject the null hypothesis. The data is not normally distributed.
wb_rating)shapiro.test(data001$wb_rating)
Shapiro-Wilk normality test
data: data001$wb_rating
W = 0.90117, p-value < 2.2e-16qqnorm(data001$wb_rating)
qqline(data001$wb_rating, col = "red")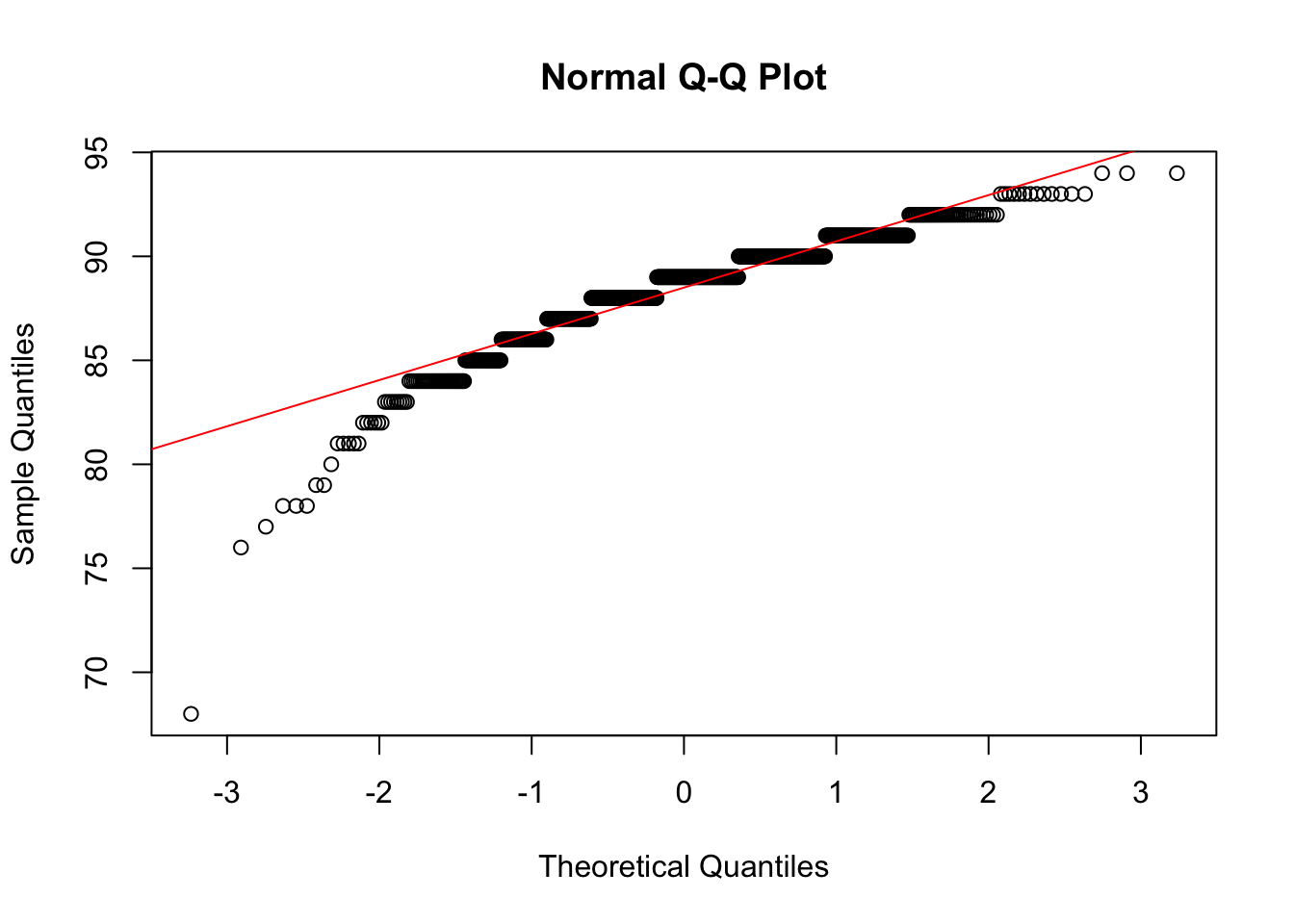
Result: The p-value is much less than 0.05, so we reject the null hypothesis. The data is not normally distributed.
diff)shapiro.test(data001$diff)
Shapiro-Wilk normality test
data: data001$diff
W = 0.90374, p-value < 2.2e-16qqnorm(data001$diff)
qqline(data001$diff, col = "red")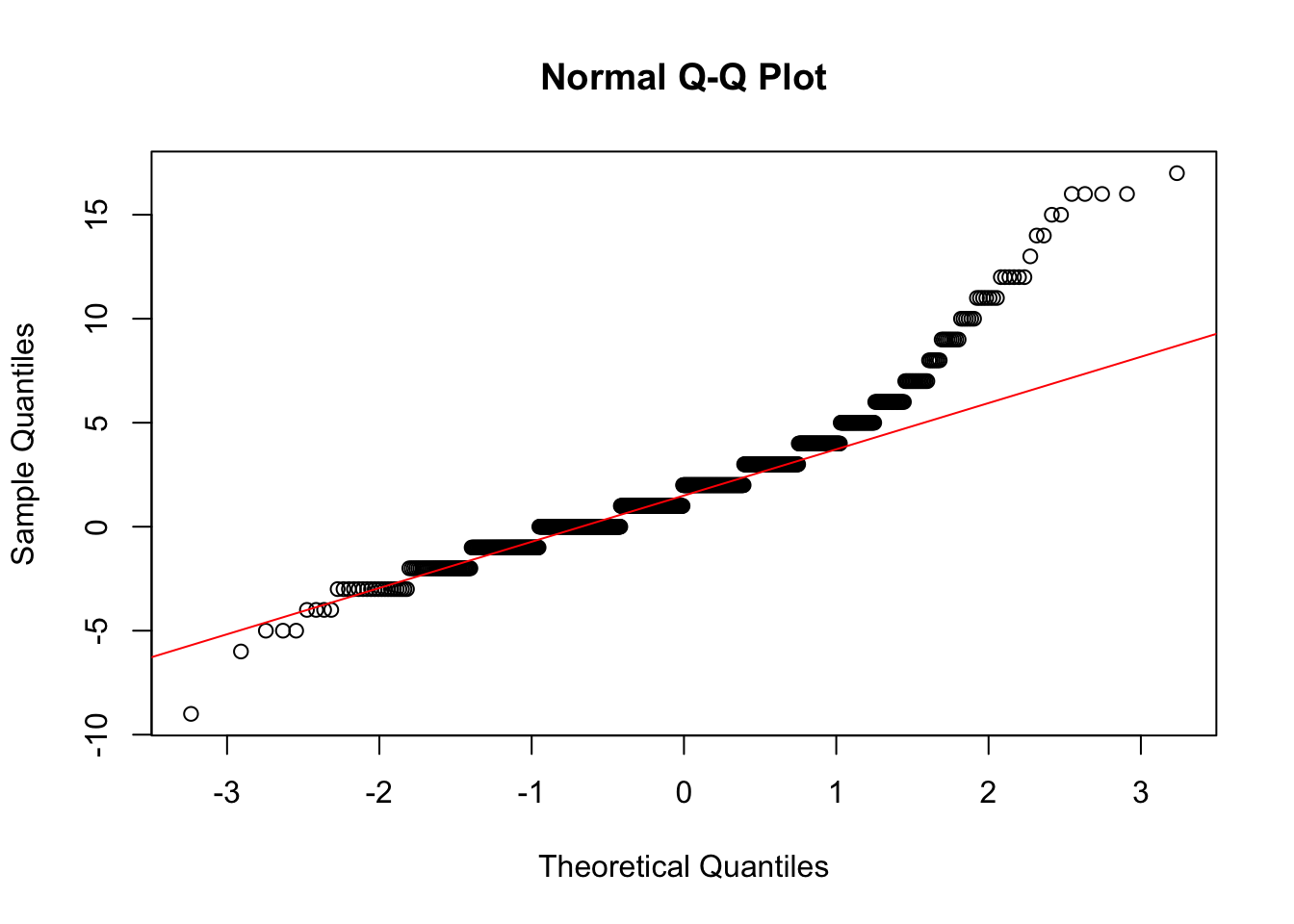
Result: The p-value is much less than 0.05, so we reject the null hypothesis. The differences are not normally distributed.
age)shapiro.test(data002$age)
Shapiro-Wilk normality test
data: data002$age
W = 0.97857, p-value = 3.565e-08qqnorm(data002$age)
qqline(data002$age, col = "red")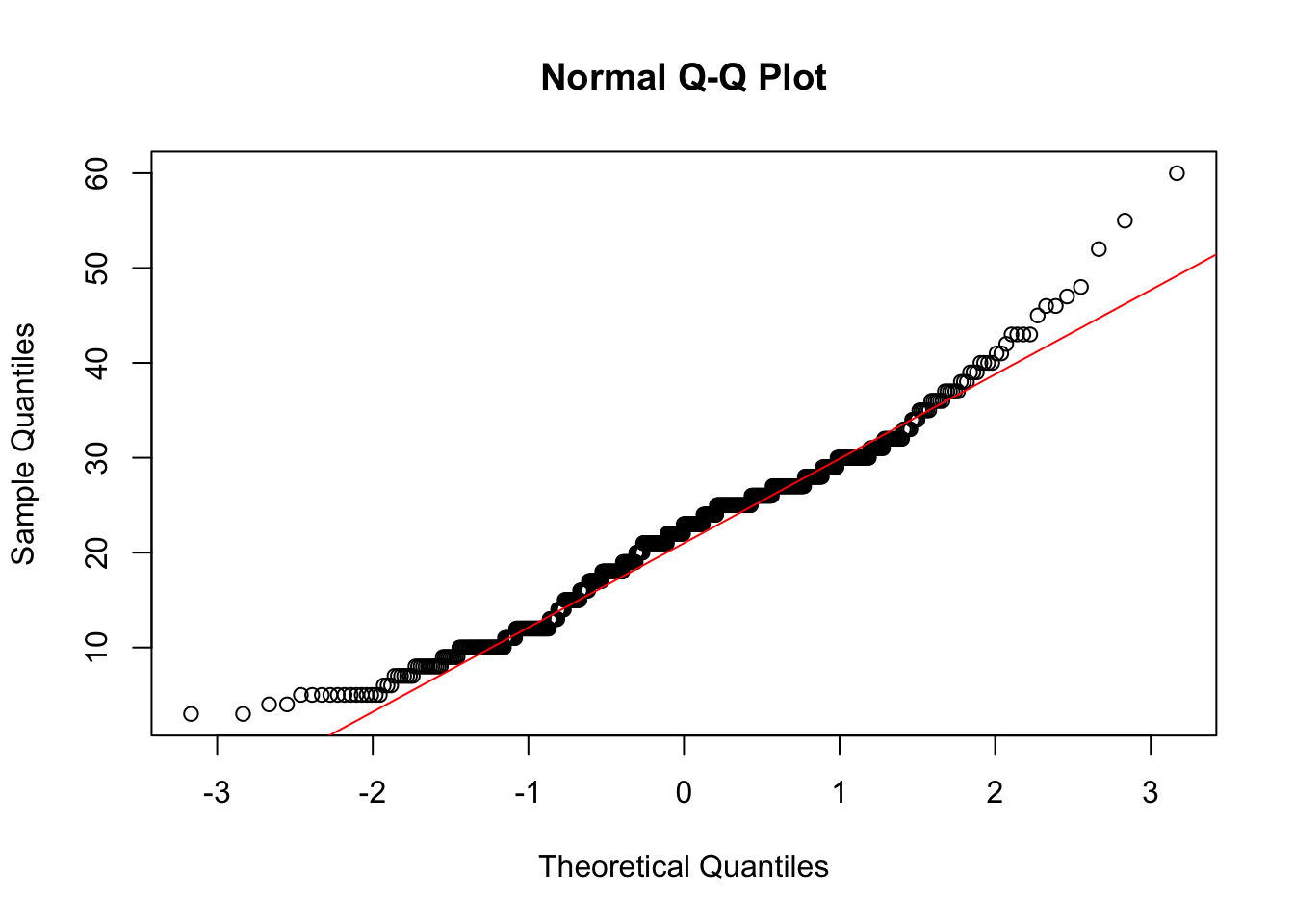
Result: The p-value is much less than 0.05, so we reject the null hypothesis. The age data is not normally distributed.
We want to determine if there is a statistically significant difference between my_rating and wb_rating. Since these are paired samples (each whisky has two ratings), a paired t-test is appropriate.
Null Hypothesis (H0): The true mean difference between the paired ratings is zero. Alternative Hypothesis (H1): The true mean difference is not zero.
mean_wb <- mean(data001$wb_rating)
mean_my <- mean(data001$my_rating)
mean_diff <- mean(data001$diff)
cat(paste("Mean wb_rating:", round(mean_wb, 2), "\n"))Mean wb_rating: 88.44 cat(paste("Mean my_rating:", round(mean_my, 2), "\n"))Mean my_rating: 86.46 cat(paste("Mean difference:", round(mean_diff, 2), "\n"))Mean difference: 1.98 t_test_paired <- t.test(data001$wb_rating, data001$my_rating, paired = TRUE)
print(t_test_paired)
Paired t-test
data: data001$wb_rating and data001$my_rating
t = 17.811, df = 826, p-value < 2.2e-16
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
1.762374 2.198932
sample estimates:
mean difference
1.980653 # Calculate Cohen's d effect size
d <- mean_diff / sd(data001$diff)
cat("Cohen's d:", round(d, 2), "\n")Cohen's d: 0.62 The paired t-test assumes that the differences between the pairs are normally distributed. Our Shapiro-Wilk test on the diff variable showed this is not the case. Therefore, we should use a non-parametric alternative, the Wilcoxon Signed-Rank Test.
Null Hypothesis (H0): The median difference between the pairs is zero.
wilcox.test(data001$wb_rating, data001$my_rating, paired = TRUE)
Wilcoxon signed rank test with continuity correction
data: data001$wb_rating and data001$my_rating
V = 204659, p-value < 2.2e-16
alternative hypothesis: true location shift is not equal to 0Conclusion: The p-value is extremely small (< 2.2e-16), confirming the result of the t-test. We reject the null hypothesis and conclude that there is a significant difference between the two sets of ratings.
Since our data is not normally distributed, we will use Spearman’s rank correlation coefficient (ρ) to measure the strength and direction of the monotonic relationship between variables.
Null Hypothesis (H0): There is no correlation between the variables.
fig <- plot_ly(
data = data001,
x = ~wb_rating,
y = ~my_rating,
text = ~whisky,
type = 'scatter',
mode = 'markers'
) %>%
layout(title = 'My Rating vs. Whiskybase Rating')
figcor_test_result <- cor.test(
data001$wb_rating,
data001$my_rating,
method = "spearman"
)
print(cor_test_result)
Spearman's rank correlation rho
data: data001$wb_rating and data001$my_rating
S = 28755402, p-value < 2.2e-16
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
0.6949614 Result: ρ = 0.68. This indicates a strong positive monotonic relationship. As my rating for a whisky increases, the Whiskybase rating also tends to increase.
fig <- plot_ly(
data = data002,
x = ~my_rating,
y = ~age,
text = ~whisky,
type = 'scatter',
mode = 'markers'
) %>%
layout(title = 'My Rating vs. Whisky Age')
figcor_test_result <- cor.test(data002$my_rating, data002$age, method = "spearman")
print(cor_test_result)
Spearman's rank correlation rho
data: data002$my_rating and data002$age
S = 27281110, p-value < 2.2e-16
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
0.4094298 Result: ρ = 0.41. This indicates a moderate positive monotonic relationship. There is a tendency for older whiskies to receive higher personal ratings.
fig <- plot_ly(
data = data002,
x = ~wb_rating,
y = ~age,
text = ~whisky,
type = 'scatter',
mode = 'markers'
) %>%
layout(title = 'Whiskybase Rating vs. Whisky Age')
figcor_test_result <- cor.test(data002$wb_rating, data002$age, method = "spearman")
print(cor_test_result)
Spearman's rank correlation rho
data: data002$wb_rating and data002$age
S = 19831159, p-value < 2.2e-16
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
0.5707033 Result: ρ = 0.57. This indicates a strong positive monotonic relationship. Older whiskies tend to have higher ratings on Whiskybase.
This study has several limitations that should be considered when interpreting the results:
Key assumptions include: - Independence of ratings between whiskies - Missing age data does not systematically bias results - The dataset represents a reasonable cross-section of whisky types
This analysis yielded several key insights:
All data variables (ratings and age) were found to be not normally distributed, necessitating the use of non-parametric tests for robust conclusions.